I've seen many FFT and STFT implementations
Why do so many FFT and STFT libraries have different outputs?Celebrating a new website
I recently purchased and set up https://metalgroove.xyz after attending a Periphery concert, to showcase my various metal-related software projects over the years
To celebrate the launch of the new website, I'm finally working on this long-awaited blog post on some of the most important algorithms in digital audio and music analysis: the Fourier transform, Fast Fourier Transform, and Short-Time Fourier Transform
FFT differences: the scaling factor
The Eigen library's FFT implementation, based on KissFFT, describes different FFT scaling factors:
Scaling: Other libraries: do not perform scaling, so there is a constant gain incurred after the forward & inverse transforms , so IFFT(FFT(x)) = Kx; this is done to avoid a vector-by-value multiply.
The downside is that algorithms that work correctly in Matlab/octave don't behave the same way once implemented in C++.
How Eigen::FFT differs: invertible scaling is performed so IFFT( FFT(x) ) = x.
Use the Eigen::FFT::Unscaled flag to change the default behavior
FFTS in pitch-detection
The FFTS library, the Fastest Fourier Transform in the South, is one of the first I used in my pitch-detection project.
Let's look at the FFT scaling factors there in the autocorrelation code:
std::complex<float> scale = 1.0f / static_cast<float>(ba->nfft);
Scale is 1/N.
KissFFT in pitchlite
The KissFFT library used in my WebAssembly pitchlite project has a different scaling behavior:
kiss_fft_cpx scale = {1.0f / (float)(ba->N * 2), 0.0f};
I'm dividing by 1/(N/2) now, probably because it's a real FFT that has nfft/2 + 1 points?
Already working on these two libraries confused me because of their different scaling behaviors.
STFT differences: too many to count
The Short-Time Fourier Transform (STFT), aka Local Fourier Transform or Gabor Transform, is a form of time-frequency analysis.
In a nutshell
The Fourier Transform or Fourier analysis gives pure frequency information, devoid of time or temporal information. The STFT is useful for introducing joint time-frequency analysis by splitting a signal into chunks that are consecutive in time and obtaining frequency information per-chunk. This way, we get an idea of the evolving frequency contents over time
This image (from MATLAB) shows the operation of an STFT: 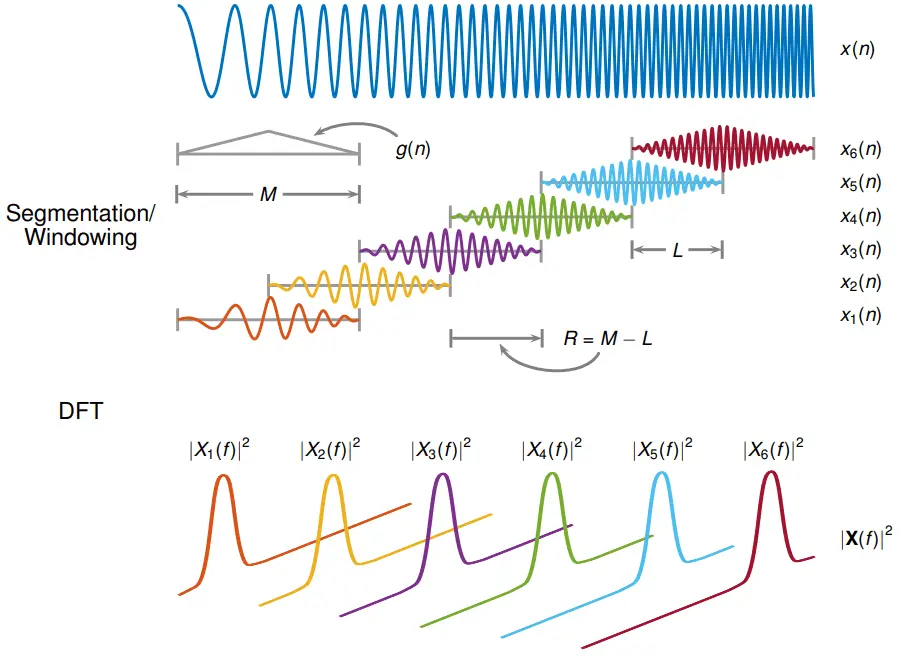
Let's take a look at some popular STFT libraries and their parameters:
- MATLAB:
s = stft(x) returns the Short-Time Fourier Transform (STFT) of x. - scipy:
scipy.signal.stft(x, fs=1.0, window='hann', nperseg=256, noverlap=None, nfft=None, detrend=False, return_onesided=True, boundary='zeros', padded=True, axis=-1, scaling='spectrum') - torch/pytorch:
torch.stft(input, n_fft, hop_length=None, win_length=None, window=None, center=True, pad_mode='reflect', normalized=False, onesided=None, return_complex=None) - librosa:
librosa.stft(y, *, n_fft=2048, hop_length=None, win_length=None, window='hann', center=True, dtype=None, pad_mode='constant', out=None)
MATLAB is the gold standard - easy to use.
The others are almost a caricature of bad APIs. Hop and noverlap are synonyms, as are normalizing and scaling. We have to supply padding, "center mode", and too many knobs and parameters. I find this absurd and a huge source of potential confusion and errors.
Center mode
Torch explains it:
If center is True (default), input will be padded on both sides so that the tt-th frame is centered at time t×hop_lengtht×hop_length. Otherwise, the tt-th frame begins at time t×hop_lengtht×hop_length.
Also, Brian McFee in this good issue on Librosa:
I'm not exactly sure what the question is here, but I'll respond to the points as I interpret them.
Number of frames is different based on center parameter. This difference distracts a little since there is also behaviour of dropping last windows if there are not enough points till n_fft (when center=False). With center=True for several last fft windows there even won't be enough samples, but it produces anyway.
When center=True, the signal is padded with zeros, so yes, there may be more frames. This is correct and expected behavior.
Hand-constructing an STFT from the FFT
In a string of related projects - Real-Time-HPSS, Music-Sep-TF, Zen - I build a realtime "sliding" STFT where the current Nth input frame of music has an FFT applied and appended to an STFT structure that contains the last N-1 frames:
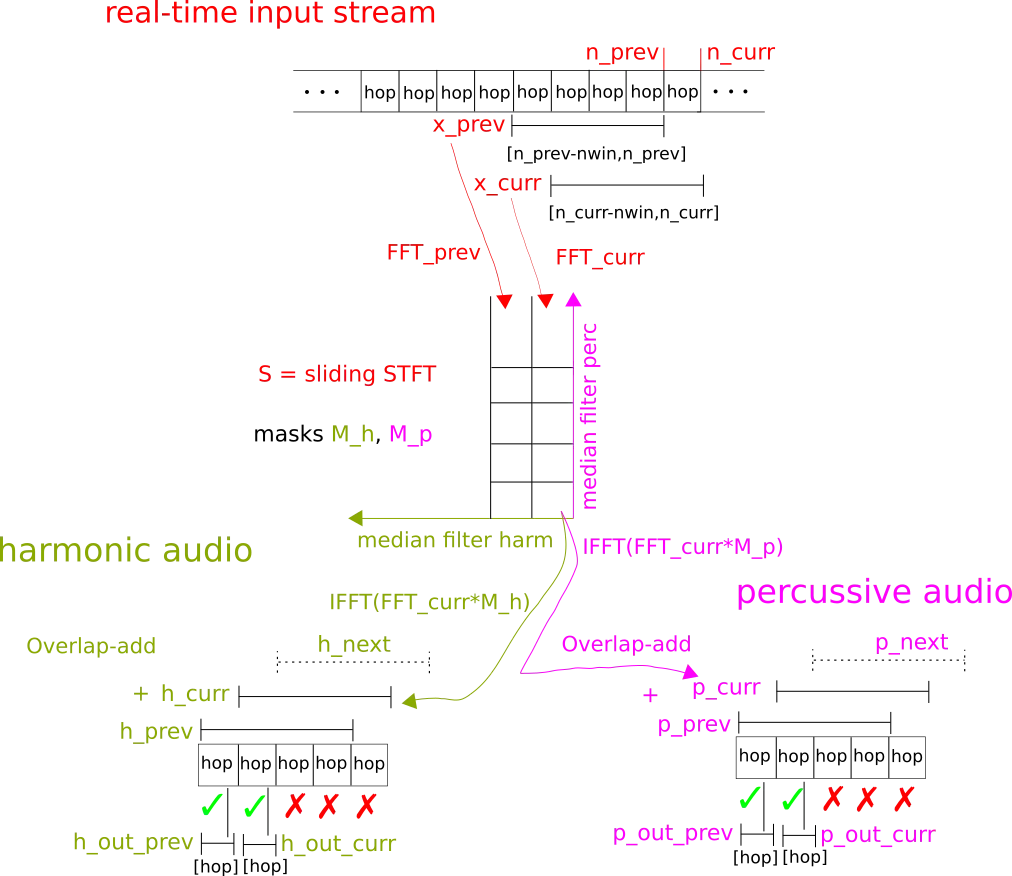
In MATLAB
In Real-Time-HPSS's MATLAB code, it looks like this:
win = sqrt(hann(nwin, "periodic"));
lHarm = 0.2/((nfft - hop)/fs); % 200ms in samples
STFT = zeros(nfft, ceil(lHarm/2)); % preallocate the sliding stft for collecting 200ms of data
% nwin-frame size ringbuffer to store input waveform
x = zeros(nwin, 1);
eof = 0;
while eof == 0
[nextHop, eof] = wavIn(); % get next chunk from wav file
tic
x = vertcat(x(hop+1:nwin), nextHop); % append latest hop samples
X = fft(x.*win, nfft); Xhalf = X(1:(nfft/2)); % FFT current frame
STFT = STFT(:, 2:size(STFT, 2)); % remove oldest stft frame
STFT(:, size(STFT, 2)+1) = X; % append latest frame
Notice I'm scaling the FFT with 1/(nfft/2) which reminds of of the KissFFT scaling factor.
In Python
Python code:
Buggy!
The Python code is buggy due to my misuse of the scaling factor. This is to show that after years of futzing around with different FFTs and STFTs, it's easy to fuck up
self.window = numpy.sqrt(scipy.signal.hann(self.nwin, sym=False))
self.eps = numpy.finfo(numpy.float32).eps
self.lharm = int(numpy.round(0.2 / ((nfft - hop) / fs)))
if self.lharm % 2 == 0:
self.lharm += 1
if self.lperc % 2 == 0:
self.lperc += 1
self.stft = numpy.zeros(
shape=(nfft, int(numpy.ceil(self.lharm / 2))), dtype=numpy.csingle
) # f32, f32 complex
self.x = numpy.zeros(shape=(nwin,), dtype=numpy.float32)
def process_next_hop(self, hop):
if len(hop) != self.hop:
raise ValueError("feed me hop-sized chunks, please")
self.x = numpy.concatenate((self.x[self.hop :], hop))
xw = self.x * self.window
X = numpy.fft.fft(xw, self.nfft)
self.stft = numpy.concatenate(
(self.stft[:, 1:], numpy.reshape(X, (self.nfft, 1))), 1
)
In C++
In Zen, the C++ code uses an FFT wrapper - probably poorly named for FFT Wrapper rather than FFTW, the Fastest Fourier Transform in the West and probably one of the best-known FFT libraries in the world.
It wraps around the IPP (Intel Performance Primitives) and cuFFT (NVIDIA CUDA FFT) FFT functions.
cuFFT GPU wrapper:
class FFTC2CWrapperGPU {
public:
std::size_t nfft;
thrust::device_vector<thrust::complex<float>> fft_vec;
FFTC2CWrapperGPU(std::size_t nfft)
: nfft(nfft)
, fft_vec(nfft)
, fft_ptr(( cuFloatComplex* )thrust::raw_pointer_cast(
fft_vec.data()))
{
cufftPlan1d(&plan, nfft, CUFFT_C2C, 1);
}
void forward()
{
cufftExecC2C(plan, fft_ptr, fft_ptr, CUFFT_FORWARD);
}
void backward()
{
cufftExecC2C(plan, fft_ptr, fft_ptr, CUFFT_INVERSE);
}
private:
cuFloatComplex* fft_ptr;
cufftHandle plan;
};
Note, no scaling.
IPP CPU wrapper:
class FFTC2CWrapperCPU {
public:
std::size_t nfft;
std::vector<thrust::complex<float>> fft_vec;
FFTC2CWrapperCPU(std::size_t nfft)
: nfft(nfft)
, fft_order(( int )log2(nfft))
, fft_vec(nfft)
, fft_ptr(( Ipp32fc* )fft_vec.data())
, p_mem_spec(nullptr)
, p_mem_init(nullptr)
, p_mem_buffer(nullptr)
, size_spec(0)
, size_init(0)
, size_buffer(0)
{
IppStatus ipp_status = ippsFFTGetSize_C_32fc(
fft_order, IPP_FFT_NODIV_BY_ANY, ippAlgHintNone,
&size_spec, &size_init, &size_buffer);
if (ipp_status != ippStsNoErr) {
std::cerr << "ippFFTGetSize error: " << ipp_status << ", "
<< ippGetStatusString(ipp_status) << std::endl;
std::exit(-1);
}
if (size_init > 0)
p_mem_init = ( Ipp8u* )ippMalloc(size_init);
if (size_buffer > 0)
p_mem_buffer = ( Ipp8u* )ippMalloc(size_buffer);
if (size_spec > 0)
p_mem_spec = ( Ipp8u* )ippMalloc(size_spec);
ipp_status = ippsFFTInit_C_32fc(
&fft_spec, fft_order, IPP_FFT_NODIV_BY_ANY, ippAlgHintNone,
p_mem_spec, p_mem_init);
if (ipp_status != ippStsNoErr) {
std::cerr << "ippFFTInit error: " << ipp_status << ", "
<< ippGetStatusString(ipp_status) << std::endl;
std::exit(-1);
}
if (size_init > 0)
ippFree(p_mem_init);
}
~FFTC2CWrapperCPU()
{
if (size_buffer > 0)
ippFree(p_mem_buffer);
if (size_spec > 0)
ippFree(p_mem_spec);
}
void forward()
{
ippsFFTFwd_CToC_32fc_I(fft_ptr, fft_spec, p_mem_buffer);
}
void backward()
{
ippsFFTInv_CToC_32fc_I(fft_ptr, fft_spec, p_mem_buffer);
}
private:
int fft_order;
Ipp32fc* fft_ptr;
IppsFFTSpec_C_32fc* fft_spec;
Ipp8u* p_mem_spec;
Ipp8u* p_mem_init;
Ipp8u* p_mem_buffer;
int size_spec;
int size_init;
int size_buffer;
Then, I use Thrust for the underlying CPU or GPU-agnostic sliding STFT calculation:
// append latest hop samples e.g. input = input[hop:] + current_hop
thrust::copy(input.begin() + hop, input.end(), input.begin());
thrust::copy(in_hop, in_hop + hop, input.begin() + hop);
// populate curr_fft with input .* square root von hann window
thrust::transform(input.begin(), input.end(), window.window.begin(),
fft.fft_vec.begin(),
zen::internal::hps::window_functor());
// zero out the second half of the fft
thrust::fill(fft.fft_vec.begin() + nwin, fft.fft_vec.end(),
thrust::complex<float>{0.0, 0.0});
// perform the fft
fft.forward();
// rotate stft matrix to move the oldest column to the end
// copy curr_fft into the last column of the stft
thrust::copy(
sliding_stft.begin() + nfft, sliding_stft.end(), sliding_stft.begin());
thrust::copy(
fft.fft_vec.begin(), fft.fft_vec.end(), sliding_stft.end() - nfft);
Replicating Torch FFT with Eigen C++
In umx.cpp and demucs.cpp, my goal was to replicate the inference of the PyTorch neural networks Open-Unmix and Demucs respectively.
In PyTorch
Open-Unmix STFT using PyTorch:
self.stft, self.istft = make_filterbanks(
n_fft=n_fft,
n_hop=n_hop,
center=True,
method=filterbank,
sample_rate=sample_rate,
)
def make_filterbanks(n_fft=4096, n_hop=1024, center=False, sample_rate=44100.0, method="torch"):
window = nn.Parameter(torch.hann_window(n_fft), requires_grad=False)
encoder = TorchSTFT(n_fft=n_fft, n_hop=n_hop, window=window, center=center)
decoder = TorchISTFT(n_fft=n_fft, n_hop=n_hop, window=window, center=center)
Demucs STFT using PyTorch:
import torch as th
def spectro(x, n_fft=512, hop_length=None, pad=0):
*other, length = x.shape
x = x.reshape(-1, length)
is_mps = x.device.type == 'mps'
if is_mps:
x = x.cpu()
z = th.stft(x,
n_fft * (1 + pad),
hop_length or n_fft // 4,
window=th.hann_window(n_fft).to(x),
win_length=n_fft,
normalized=True,
center=True,
return_complex=True,
pad_mode='reflect')
_, freqs, frame = z.shape
return z.view(*other, freqs, frame)
def ispectro(z, hop_length=None, length=None, pad=0):
*other, freqs, frames = z.shape
n_fft = 2 * freqs - 2
z = z.view(-1, freqs, frames)
win_length = n_fft // (1 + pad)
is_mps = z.device.type == 'mps'
if is_mps:
z = z.cpu()
x = th.istft(z,
n_fft,
hop_length,
window=th.hann_window(win_length).to(z.real),
win_length=win_length,
normalized=True,
length=length,
center=True)
_, length = x.shape
return x.view(*other, length)
In Eigen C++
In umx.cpp using Eigen's FFT module (which is based on KissFFT):
// forward declaration of inner stft
void stft_inner(struct umxcpp::stft_buffers &stft_buf, Eigen::FFT<float> &cfg);
void istft_inner(struct umxcpp::stft_buffers &stft_buf, Eigen::FFT<float> &cfg);
// reflect padding
void pad_signal(struct umxcpp::stft_buffers &stft_buf)
{
// copy from stft_buf.padded_waveform_mono_in+pad into stft_buf.pad_start,
// stft_buf.pad_end
std::copy_n(stft_buf.padded_waveform_mono_in.begin() + stft_buf.pad,
stft_buf.pad, stft_buf.pad_start.begin());
std::copy_n(stft_buf.padded_waveform_mono_in.end() - 2 * stft_buf.pad,
stft_buf.pad, stft_buf.pad_end.begin());
std::reverse(stft_buf.pad_start.begin(), stft_buf.pad_start.end());
std::reverse(stft_buf.pad_end.begin(), stft_buf.pad_end.end());
// copy stft_buf.pad_start into stft_buf.padded_waveform_mono_in
std::copy_n(stft_buf.pad_start.begin(), stft_buf.pad,
stft_buf.padded_waveform_mono_in.begin());
// copy stft_buf.pad_end into stft_buf.padded_waveform_mono_in
std::copy_n(stft_buf.pad_end.begin(), stft_buf.pad,
stft_buf.padded_waveform_mono_in.end() - stft_buf.pad);
}
Eigen::FFT<float> get_fft_cfg()
{
Eigen::FFT<float> cfg;
cfg.SetFlag(Eigen::FFT<float>::Speedy);
cfg.SetFlag(Eigen::FFT<float>::HalfSpectrum);
cfg.SetFlag(Eigen::FFT<float>::Unscaled);
return cfg;
}
void umxcpp::stft(struct stft_buffers &stft_buf)
{
// get the fft config
Eigen::FFT<float> cfg = get_fft_cfg();
/*****************************************/
/* operate on each channel sequentially */
/*****************************************/
for (int channel = 0; channel < 2; ++channel)
{
Eigen::VectorXf row_vec = stft_buf.waveform.row(channel);
std::copy_n(row_vec.data(), row_vec.size(),
stft_buf.padded_waveform_mono_in.begin() + stft_buf.pad);
// apply padding equivalent to center padding with center=True
// in torch.stft:
// https://pytorch.org/docs/stable/generated/torch.stft.html
// reflect pads stft_buf.padded_waveform_mono in-place
pad_signal(stft_buf);
// does forward fft on stft_buf.padded_waveform_mono, stores spectrum in
// complex_spec_mono
stft_inner(stft_buf, cfg);
for (int i = 0; i < stft_buf.nb_frames; ++i)
{
for (int j = 0; j < stft_buf.nb_bins; ++j)
{
stft_buf.spec(channel, i, j) = stft_buf.complex_spec_mono[i][j];
}
}
}
}
void umxcpp::istft(struct stft_buffers &stft_buf)
{
// get the fft config
Eigen::FFT<float> cfg = get_fft_cfg();
/*****************************************/
/* operate on each channel sequentially */
/*****************************************/
for (int channel = 0; channel < 2; ++channel)
{
// Populate the nested vectors
for (int i = 0; i < stft_buf.nb_frames; ++i)
{
for (int j = 0; j < stft_buf.nb_bins; ++j)
{
stft_buf.complex_spec_mono[i][j] = stft_buf.spec(channel, i, j);
}
}
// does inverse fft on stft_buf.complex_spec_mono, stores waveform in
// padded_waveform_mono
istft_inner(stft_buf, cfg);
// copies waveform_mono into stft_buf.waveform past first pad samples
stft_buf.waveform.row(channel) = Eigen::Map<Eigen::MatrixXf>(
stft_buf.padded_waveform_mono_out.data() + stft_buf.pad, 1,
stft_buf.padded_waveform_mono_out.size() - FFT_WINDOW_SIZE);
}
}
void stft_inner(struct umxcpp::stft_buffers &stft_buf, Eigen::FFT<float> &cfg)
{
int frame_idx = 0;
// Loop over the waveform with a stride of hop_size
for (std::size_t start = 0;
start <=
stft_buf.padded_waveform_mono_in.size() - umxcpp::FFT_WINDOW_SIZE;
start += umxcpp::FFT_HOP_SIZE)
{
// Apply window and run FFT
for (int i = 0; i < umxcpp::FFT_WINDOW_SIZE; ++i)
{
stft_buf.windowed_waveform_mono[i] =
stft_buf.padded_waveform_mono_in[start + i] *
stft_buf.window[i];
}
cfg.fwd(stft_buf.complex_spec_mono[frame_idx++],
stft_buf.windowed_waveform_mono);
}
}
void istft_inner(struct umxcpp::stft_buffers &stft_buf, Eigen::FFT<float> &cfg)
{
// clear padded_waveform_mono
std::fill(stft_buf.padded_waveform_mono_out.begin(),
stft_buf.padded_waveform_mono_out.end(), 0.0f);
// Loop over the input with a stride of (hop_size)
for (std::size_t start = 0;
start < stft_buf.nb_frames * umxcpp::FFT_HOP_SIZE;
start += umxcpp::FFT_HOP_SIZE)
{
// Run iFFT
cfg.inv(stft_buf.windowed_waveform_mono,
stft_buf.complex_spec_mono[start / umxcpp::FFT_HOP_SIZE]);
// Apply window and add to output
for (int i = 0; i < umxcpp::FFT_WINDOW_SIZE; ++i)
{
// x[start+i] is the sum of squared window values
// https://github.com/librosa/librosa/blob/main/librosa/core/spectrum.py#L613
// 1e-8f is a small number to avoid division by zero
stft_buf.padded_waveform_mono_out[start + i] +=
stft_buf.windowed_waveform_mono[i] * stft_buf.window[i] * 1.0f /
float(umxcpp::FFT_WINDOW_SIZE) /
(stft_buf.normalized_window[start + i] + 1e-8f);
}
}
}
I remember having particular trouble with the reverse overlap-add in the iSTFT until reading the librosa code.
In demucs.cpp (again, using Eigen FFT based on KissFFT):
// forward declaration of inner stft
void stft_inner(struct demucscpp::stft_buffers &stft_buf,
Eigen::FFT<float> &cfg);
void istft_inner(struct demucscpp::stft_buffers &stft_buf,
Eigen::FFT<float> &cfg);
// reflect padding
void pad_signal(struct demucscpp::stft_buffers &stft_buf)
{
// copy from stft_buf.padded_waveform_mono_in+pad into stft_buf.pad_start,
// stft_buf.pad_end
std::copy_n(stft_buf.padded_waveform_mono_in.begin() + stft_buf.pad,
stft_buf.pad, stft_buf.pad_start.begin());
std::copy_n(stft_buf.padded_waveform_mono_in.end() - 2 * stft_buf.pad,
stft_buf.pad, stft_buf.pad_end.begin());
std::reverse(stft_buf.pad_start.begin(), stft_buf.pad_start.end());
std::reverse(stft_buf.pad_end.begin(), stft_buf.pad_end.end());
// copy stft_buf.pad_start into stft_buf.padded_waveform_mono_in
std::copy_n(stft_buf.pad_start.begin(), stft_buf.pad,
stft_buf.padded_waveform_mono_in.begin());
// copy stft_buf.pad_end into stft_buf.padded_waveform_mono_in
std::copy_n(stft_buf.pad_end.begin(), stft_buf.pad,
stft_buf.padded_waveform_mono_in.end() - stft_buf.pad);
}
Eigen::FFT<float> get_fft_cfg()
{
Eigen::FFT<float> cfg;
cfg.SetFlag(Eigen::FFT<float>::Speedy);
// cfg.SetFlag(Eigen::FFT<float>::HalfSpectrum);
// cfg.SetFlag(Eigen::FFT<float>::Unscaled);
return cfg;
}
void demucscpp::stft(struct stft_buffers &stft_buf)
{
// get the fft config
Eigen::FFT<float> cfg = get_fft_cfg();
/*****************************************/
/* operate on each channel sequentially */
/*****************************************/
for (int channel = 0; channel < 2; ++channel)
{
Eigen::VectorXf row_vec = stft_buf.waveform.row(channel);
std::copy_n(row_vec.data(), row_vec.size(),
stft_buf.padded_waveform_mono_in.begin() + stft_buf.pad);
// apply padding equivalent to center padding with center=True
// in torch.stft:
// https://pytorch.org/docs/stable/generated/torch.stft.html
// reflect pads stft_buf.padded_waveform_mono in-place
pad_signal(stft_buf);
// does forward fft on stft_buf.padded_waveform_mono, stores spectrum in
// complex_spec_mono
stft_inner(stft_buf, cfg);
for (int i = 0; i < stft_buf.nb_bins; ++i)
{
for (int j = 0; j < stft_buf.nb_frames; ++j)
{
stft_buf.spec(channel, i, j) = stft_buf.complex_spec_mono[j][i];
}
}
}
}
void demucscpp::istft(struct stft_buffers &stft_buf)
{
// get the fft config
Eigen::FFT<float> cfg = get_fft_cfg();
/*****************************************/
/* operate on each channel sequentially */
/*****************************************/
for (int channel = 0; channel < 2; ++channel)
{
// Populate the nested vectors
for (int i = 0; i < stft_buf.nb_bins; ++i)
{
for (int j = 0; j < stft_buf.nb_frames; ++j)
{
stft_buf.complex_spec_mono[j][i] = stft_buf.spec(channel, i, j);
}
}
// does inverse fft on stft_buf.complex_spec_mono, stores waveform in
// padded_waveform_mono
istft_inner(stft_buf, cfg);
// copies waveform_mono into stft_buf.waveform past first pad samples
stft_buf.waveform.row(channel) = Eigen::Map<Eigen::MatrixXf>(
stft_buf.padded_waveform_mono_out.data() + stft_buf.pad, 1,
stft_buf.padded_waveform_mono_out.size() - FFT_WINDOW_SIZE);
}
}
void stft_inner(struct demucscpp::stft_buffers &stft_buf,
Eigen::FFT<float> &cfg)
{
int frame_idx = 0;
// Loop over the waveform with a stride of hop_size
for (std::size_t start = 0;
start <=
stft_buf.padded_waveform_mono_in.size() - demucscpp::FFT_WINDOW_SIZE;
start += demucscpp::FFT_HOP_SIZE)
{
// Apply window and run FFT
for (int i = 0; i < demucscpp::FFT_WINDOW_SIZE; ++i)
{
stft_buf.windowed_waveform_mono[i] =
stft_buf.padded_waveform_mono_in[start + i] *
stft_buf.window[i];
}
cfg.fwd(stft_buf.complex_spec_mono[frame_idx],
stft_buf.windowed_waveform_mono);
// now scale stft_buf.complex_spec_mono[frame_idx] by 1.0f /
// sqrt(float(FFT_WINDOW_SIZE)))
for (int i = 0; i < demucscpp::FFT_WINDOW_SIZE / 2 + 1; ++i)
{
stft_buf.complex_spec_mono[frame_idx][i] *=
1.0f / sqrt(float(demucscpp::FFT_WINDOW_SIZE));
}
frame_idx++;
}
}
void istft_inner(struct demucscpp::stft_buffers &stft_buf,
Eigen::FFT<float> &cfg)
{
// clear padded_waveform_mono
std::fill(stft_buf.padded_waveform_mono_out.begin(),
stft_buf.padded_waveform_mono_out.end(), 0.0f);
// Loop over the input with a stride of (hop_size)
for (int start = 0; start < stft_buf.nb_frames * demucscpp::FFT_HOP_SIZE;
start += demucscpp::FFT_HOP_SIZE)
{
int frame_idx = start / demucscpp::FFT_HOP_SIZE;
// undo sqrt(nfft) scaling
for (int i = 0; i < demucscpp::FFT_WINDOW_SIZE / 2 + 1; ++i)
{
stft_buf.complex_spec_mono[frame_idx][i] *=
sqrt(float(demucscpp::FFT_WINDOW_SIZE));
}
// Run iFFT
cfg.inv(stft_buf.windowed_waveform_mono,
stft_buf.complex_spec_mono[frame_idx]);
// Apply window and add to output
for (int i = 0; i < demucscpp::FFT_WINDOW_SIZE; ++i)
{
// x[start+i] is the sum of squared window values
// https://github.com/librosa/librosa/blob/main/librosa/core/spectrum.py#L613
// 1e-8f is a small number to avoid division by zero
stft_buf.padded_waveform_mono_out[start + i] +=
stft_buf.windowed_waveform_mono[i] * stft_buf.window[i] * 1.0f /
float(demucscpp::FFT_WINDOW_SIZE) /
(stft_buf.normalized_window[start + i] + 1e-8f);
}
}
}
Differences between them
In umx.cpp, I enable the Eigen FFT options of HalfSpectrum and Unscaled. In demucs.cpp, I don't have those options enabled. I also add some of my own scaling:
// in forward fft
// now scale stft_buf.complex_spec_mono[frame_idx] by 1.0f /
// sqrt(float(FFT_WINDOW_SIZE)))
for (int i = 0; i < demucscpp::FFT_WINDOW_SIZE / 2 + 1; ++i)
{
stft_buf.complex_spec_mono[frame_idx][i] *=
1.0f / sqrt(float(demucscpp::FFT_WINDOW_SIZE));
}
frame_idx++;
// in reverse fft
int frame_idx = start / demucscpp::FFT_HOP_SIZE;
// undo sqrt(nfft) scaling
for (int i = 0; i < demucscpp::FFT_WINDOW_SIZE / 2 + 1; ++i)
{
stft_buf.complex_spec_mono[frame_idx][i] *=
sqrt(float(demucscpp::FFT_WINDOW_SIZE));
}
I had to do this out of necessity to make the values match.
Conclusion
This is all very confusing and I wish every library used the same function signatures and APIs and output scaling for the FFT and STFT.