Ignorance is BLISs
Exploring different BLAS library backends (OpenBLAS, AOCL BLIS, Intel MKL) for C++ Eigen project demucs.cpp on my AMD Zen 3 5950X. Post 1 in the freemusicdemixer.com seriesTaking freemusicdemixer.com seriously
Post 1 in a series describing the journey of my website and main project, https://freemusicdemixer.com
Taking freemusicdemixer.com seriously
In June 2023, I began working on umx.cpp, a C++ version of the Open-Unmix PyTorch neural network for music demixing. The idea came from llama.cpp, and from my desire to write C++ neural network code and learn deeper PyTorch internals.
Once I had a working copy of umx.cpp, a friend mentioned WebAssembly to me, and I wanted to use umx.cpp in a WebAssembly application. Thus, freemusicdemixer.com was born: 
In fact, before I even owned the subdomain, my self-promotion went slightly viral when it was exposed simply under my main GitHub pages site, sevag.xyz/free-music-demixer. Open-Unmix is great, but underpowered these days, or lower quality than newer algorithms, such as Demucs v4.
I committed to creating demucs.cpp, and it was a huge moment for me to get it successfully running and integrated on freemusicdemixer in December 2023. I have big plans for the site, in multiple facets:
- Improving the demixing quality and algorithms
- Improving the running time, making it faster, or making it consume less memory (and thus support larger tracks)
- Getting it running on more devices
I normally drop a project soon after it achieves a blip of attention and/or success; close the chapter, lessons learned, move on. This time, I have a feeling that I can put more energy into this project and have it pay off.
The freemusicdemixer mission
I want the whole world to experience the usefulness of the Demucs AI model in lightweight private inference on a static website, without needing a beefy computer or knowledge of how to set up complicated software projects.
Intro to demucs.cpp
My project, demucs.cpp, implements the inference of a PyTorch neural network Demucs using the Eigen linear algebra library for tensor and matrix operations.
I had a few reasons for this rewrite, mostly relating to the downstream WebAssembly application https://freemusicdemixer.com:
- I needed a low-memory inference step (due to the 4 GB max memory WebAssembly constraint)
- I needed simple C++ code (standard library/STL and Eigen only) that could be compiled to WebAssembly (versus. heavyweight tensor/NN libraries like the C++ Torch or ONNX)
- I wanted to learn PyTorch internals by handwriting C++ inference
You can see my Demucs announcement post on the freemusicdemixer site where I describe how far I got in making the code efficient, ultimately leading to GEMM (Generalized Matrix Multiplication) being the main bottleneck.
This is a good thing! Once we have the code written such that matrix multiplication dominates the running time, we can then apply different methods or explorations on how to speed that up.
Intro to BLAS libraries
BLAS, or "Basic Linear Algebra Subprograms", refers to libraries that implement a well-known set of basic linear algebra functions (matrix-matrix, matrix-vector multiplication, etc.) that are typically very well-optimized to specific CPU architectures. The original was written in Fortran, and the same Fortran API is used as a standard by the various C implementations.
If you're using numerical code (e.g. NumPy, PyTorch, Intel MKL, etc.) you're either directly or indirectly benefiting from BLAS libraries.
OpenBLAS is a popular choice that currently comes bundled with NumPy to accelerate its linear algebra. Intel MKL, or Math Kernel Library, implements BLAS functions that are optimized for Intel CPU architectures. These also help AMD CPUs, since both manufacturers implement common SIMD (single-instruction-multiple-data) instructions for x86_64 i.e. AVX.
MKL_DEBUG_CPU_TYPE=5
There was a time where a hack was making the rounds that you have to set MKL_DEBUG_CPU_TYPE=5: this article describes it. I included it in the benchmarks on this post for fun. This should no longer be relevant, with Intel now helping Zen, not intentionally crippling it.
The more current blis is a new (2023) award-winning academic project that reimagines BLAS (but also implements BLAS). BLIS stands for BLAS-like Library Instantiation Software, and it implements a set of optimized common sub-routines that can be used to compose BLAS APIs (and also includes a BLAS API). This is also the pun from the title of this post.
Speaking of Intel MKL, AMD uses BLIS to create AOCL-BLAS, where AOCL stands for AMD Optimized CPU Libraries:
BLIS, also known as "vanilla BLIS" or "upstream BLIS," is maintained by its original developer (with the support of others) in the Science of High-Performance Computing (SHPC) group within the The Oden Institute for Computational Engineering and Sciences at The University of Texas at Austin. In 2015, AMD reorganized many of their software library efforts around existing open source projects. BLIS was chosen as the basis for their CPU BLAS library, and an AMD-maintained fork of BLIS was established.*
*: from the blis docs. All of blis' documentation is worth reading.
Eigen and BLAS libraries
Eigen is a general C++ linear algebra library with support for matrix and tensor types and all sorts of math operations. Using Eigen, I was able to implement all of the PyTorch layers of the deep neural networks of Open-Unmix (umx.cpp) and Demucs (demucs.cpp), including the STFT, Conv2d, Multihead Attention, LSTM, BatchNorm, LayerNorm, and more.
Although Eigen implements its own BLAS functions to be self-contained, it supports the use of external BLAS libraries to bring additional speed boosts. Although it is well-optimized, it's not in the scope of a general library like Eigen to be maximally tuned to any one CPU architecture. Contrast that to AMD AOCL-BLAS or Intel MKL, which are hand-tuned to the specific hardware they run on.
BLAS and multi-core
BLAS goes hand-in-hand with multithreading. On my Linux OS (Pop!_OS 22.04), you can only install the OpenBLAS with OpenMP variant. OpenMP is another one of those well-known Fortran/C/C++ libraries for scientific computing; specifically OpenMP is about parallelism.
Actually, something subpar is that OMP_NUM_THREADS (on my system, at least), is set to the total number of threads (on my 16-core, 32-thread CPU, the AMD Ryzen 5950X) - 32 in my case - which is not the best performing configuration.
Warning
OMP_NUM_THREADS should be set to the same number of physical cores
The Eigen multi-threading doc explains this phenomenon:
Warning! On most OS it is very important to limit the number of threads to the number of physical cores, otherwise significant slowdowns are expected, especially for operations involving dense matrices.
Indeed, the principle of hyper-threading is to run multiple threads (in most cases 2) on a single core in an interleaved manner. However, Eigen's matrix-matrix product kernel is fully optimized and already exploits nearly 100% of the CPU capacity. Consequently, there is no room for running multiple such threads on a single core, and the performance would drops significantly because of cache pollution and other sources of overheads.
At this stage of reading you're probably wondering why Eigen does not limit itself to the number of physical cores? This is simply because OpenMP does not allow to know the number of physical cores, and thus Eigen will launch as many threads as cores reported by OpenMP.
Enabling BLAS in demucs.cpp
For my tests, I'm using:
- OpenBLAS: libopenblas0-openmp jammy package 0.3.20
- AMD AOCL: aocl 4.1.0 gcc (to use with my gcc-compiled code), tarball downloaded from AMD
- I tried using
aoccto compile the whole thing but at the end, couldn't be bothered
- I tried using
- Intel oneAPI: version 2024.0, offline installer downloaded from Intel
- No external BLAS, using Eigen's built-in BLAS routines (this commit)
NVIDIA BLAS
No discussion of BLAS or numerical computation should be had without mentioning GPUs and NVIDIA CUDA. NVIDIA provides NVBLAS, a wrapper over cuBLAS that automatically copies data from the host (CPU) to the device (GPU). However, the point of demucs.cpp is to provide lightweight and universal inference; GPUs are not universal devices, and GPU libraries are not lightweight.
I also have GNU OpenMP installed (libgomp1 jammy package 12.3.0-1ubuntu~22.04) for Eigen's native parallelism in their included BLAS code. To enable BLAS the different BLAS variants I tested, I added blocks in CMakeLists.txt for each variant.
Starting with AMD AOCL:
if (USE_AMD_AOCL)
set(AOCL_ROOT "/home/sevagh/AMD_AOCL/aocl-linux-gcc-4.1.0")
set(BLIS_PATH "${AOCL_ROOT}/aocl-blis-linux-gcc-4.1.0/amd-blis")
set(LIBFLAME_PATH "${AOCL_ROOT}/aocl-libflame-linux-gcc-4.1.0/amd-libflame")
set(LIBMEM_PATH "${AOCL_ROOT}/aocl-libmem-linux-gcc-4.1.0/amd-libmem")
include_directories(${BLIS_PATH}/include)
include_directories(${LIBFLAME_PATH}/include)
include_directories(${LIBMEM_PATH}/include)
link_directories(${BLIS_PATH}/lib/LP64)
link_directories(${LIBFLAME_PATH}/lib/LP64)
link_directories(${LIBMEM_PATH}/lib/shared)
set(LIBRARIES_TO_LINK "-lblis-mt -lflame -laocl-libmem")
set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} -DEIGEN_USE_BLAS")
lblis-mt is the AMD AOCL blis (i.e. BLAS) library, with multi-threading support (natively uses OpenMP when linked). I also use AOCL-libmem (better memory/string functions for AMD) and libflame (probably unnecessary, I think this is the AMD AOCL LAPACK). Next, Intel MKL:
elseif (USE_INTEL_MKL)
set(INTEL_MKL_ROOT "/home/sevagh/intel/oneapi/mkl/latest")
set(INTEL_COMPILER_ROOT "/home/sevagh/intel/oneapi/compiler/latest")
include_directories("${INTEL_MKL_ROOT}/include")
link_directories("${INTEL_MKL_ROOT}/lib/intel64")
link_directories("${INTEL_COMPILER_ROOT}/lib")
set(LIBRARIES_TO_LINK "-lmkl_intel_lp64 -lmkl_intel_thread -lmkl_core -liomp5")
set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} -DEIGEN_USE_BLAS")
liomp5 (i.e. Intel-OpenMP), while AMD AOCL relies on GNU OpenMP. Next, OpenBLAS:
elseif (USE_OPENBLAS)
find_package(BLAS REQUIRED)
set(LIBRARIES_TO_LINK ${BLAS_LIBRARIES})
set(CMAKE_CXX_FLAGS_RELEASE "${CMAKE_CXX_FLAGS_RELEASE} -DEIGEN_USE_BLAS")
Finally, plain Eigen, where I do need to explicitly link OpenMP for it to be used in Eigen's included BLAS implementations:
else()
# add openmp support to regular eigen
find_package(OpenMP REQUIRED)
if(OPENMP_FOUND)
set(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} ${OpenMP_CXX_FLAGS}")
include_directories(${OpenMP_CXX_INCLUDE_DIRS})
endif()
if(OPENMP_FOUND)
set(LIBRARIES_TO_LINK ${OpenMP_CXX_LIBRARIES})
endif()
endif()
I also need to add the CXX_FLAG -DEIGEN_USE_BLAS to make Eigen use an external BLAS.
sgemm_ and sgemv_: the two BLAS functions used in demucs.cpp
The syntax of the BLAS API defines functions {s,d,c,z}gemm for single-precision (float), double-precision (double), complex, double-complex. gemm is General Matrix Multiply. gemv is General Matrix-Vector operation. In short, it means that most of the linear algebra in demucs.cpp falls under matrix-matrix or matrix-vector multiplications.
My hunch is that this lines up with the model architecture of Demucs, where the majorty of the layers are 2D convolutional layers with Nx1 rectangular kernels, i.e. vectors.
The blis docs describe the difference between gemm and gemv as follows:
Most of the interest with BLAS libraries centers around level-3 operations because they exhibit favorable ratios of floating-point operations (flops) to memory operations (memops), which allows high performance. Some applications also require level-2 computation; however, these operations are at an inherent disadvantage on modern architectures due to their less favorable flop-to-memop ratio.
In BLAS parlance, gemv is a level-2 computation and gemm is a level-3 computation, and gemv as a level-2 operation does not benefit much from parallelism because it is memory-bound:
The performance of the Level 2 BLAS routines such as the matrix-vector multiplication (symv or gemv) is memory bound and very low compared to the Level 3 BLAS routines which can achieve close to the machine’s peak performance. For example, on the Intel Xeon Phi system the performance of dgemv is about 40 Gflop/s, while for dgemm is about 1000 Gflop/s. https://icl.utk.edu/files/publications/2015/icl-utk-795-2015.pdf
Performance comparison for 1-32 threads
I didn't call this section a benchmark, because I'm not well-versed in the dark arts of benchmarking. In fact I think the common wisdom is to just measure real-world performance, so that's what I did. I used /usr/bin/time --verbose to measure the wall time, CPU time, and memory usage of demucs.cpp.main demixing a 5-second test track using different BLAS libraries, using OMP_NUM_THREADS=[1, 2, 4, 8, 16, 32].
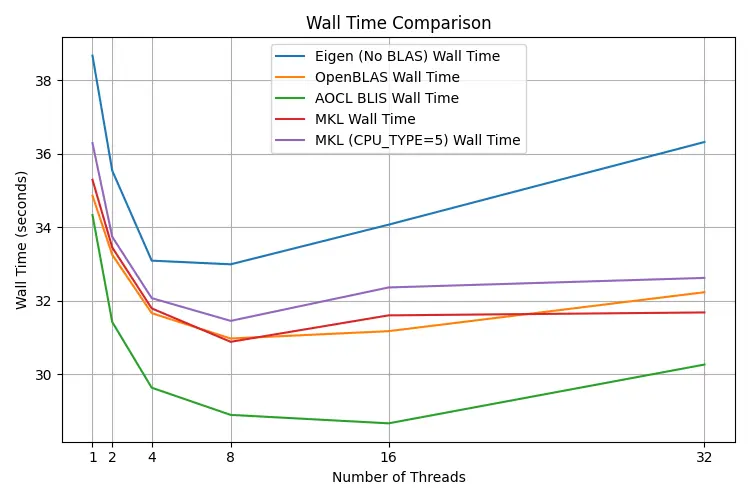
Wall time
The fastest configuration is AOCL-BLIS with 16 OMP threads. This makes sense: my CPU is an AMD Ryzen 5950X, so the manufacturer's own BLIS implementation is the fastest. OpenBLAS is in the middle of the pack. Interesting to note is that setting MKL_DEBUG_CPU_TYPE=5 performed worse than MKL without that flag.
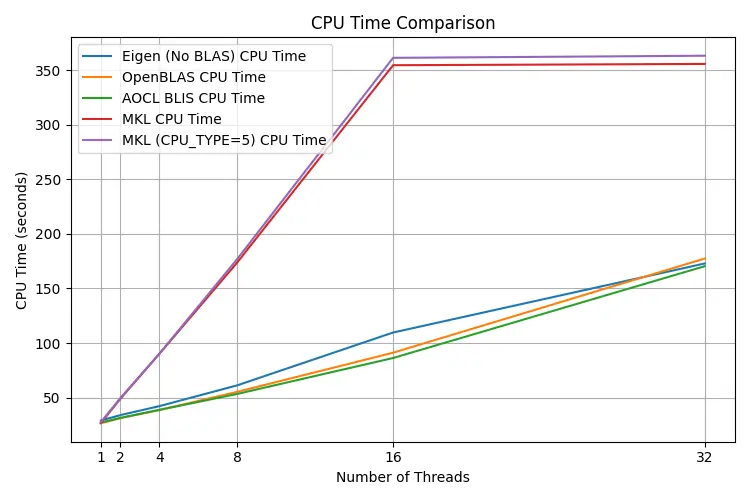
CPU time
The CPU time spent shows funny behavior for MKL, whose time spent blows up at 16 and 32 threads. The rest behave similarly.
Memory usage
Finally, in the memory usage chart, we can see that Eigen's built-in BLAS consumes by far the most memory (~2.5 GB), while OpenBLAS consumes the least.
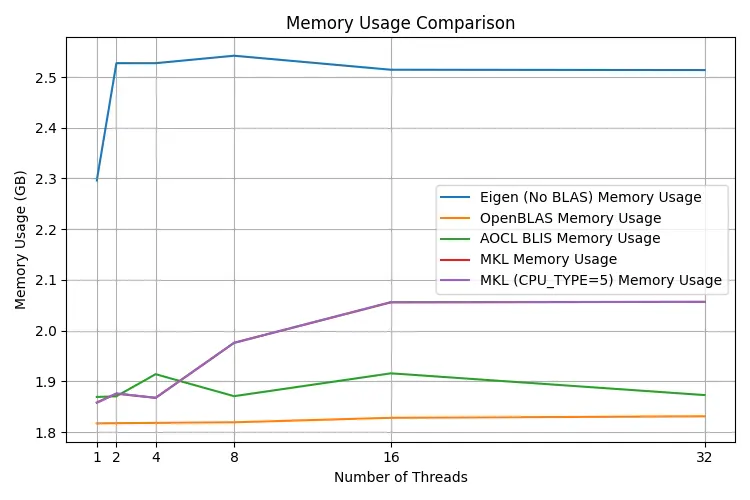
Conclusion: use OpenBLAS
AMD's AOCL-BLAS may be slightly faster but it uses more memory. At the end of the day, I'd rather stick with open-source solutions that are easier to install and distribute.