7 years of open-source projects
Tracking the evolution of my GitHub portfolio from 2014 to 2022, and how I chose new projects to work onMy GitHub account was created on 2014-08-28, in the beginning of my first full-time programming job right out of university. It was a company that emphasized free, libre, and open-source software. I recall that our conference rooms were named after Richard Stallman and Linus Torvalds. I began to fantasize about becoming well-known for my open-source code.
I thought choosing a specialization would maximize my chances of success. I landed on the topic of music software because of my background in digital signal processing (DSP) from electrical engineering, and from a brief stint of playing guitar. Actually, I thought the music software path could be a redemption arc for the abandoned guitar path.
My first commit was made on 2015-02-15 to my first open-source project: an Android pitch detection app named Pitcha. This sparked a series of projects and ideas that took me to the creation of xumx-sliCQ, whose last commit was on 2022-04-08.
For 7 years, I stayed committed to regularly releasing projects on GitHub that were useful. I define useful as "reliably delivers at least one promise made in the README file" (not all of my projects achieve this golden standard).
Initially, my guiding principle was the creation of a generalized music transcriber. It would be a piece of software that could analyze musical audio and create sheet music. To that end, I envisioned solving the puzzle piece by piece:
- Monophonic pitch tracking (single notes)
- Polyphonic pitch tracking (multiple notes/chords)
- Beat tracking
- Rhythm detection
- Tempo estimation
- Music source separation, to isolate drums from instruments and improve all of the above tasks
Over time, learning that this would be a difficult task for the entire industry of music researchers to solve let alone me working alone, I changed tracks. I came up with a content calendar (or an evolving list of topics and projects to work on) that I distilled from looking at the requirements for software engineering job openings in audio signal processing, music information retrieval, and related fields.
All of my projects are released on my GitHub account. I have 40 source repositories on GitHub, and this doesn't include many projects that were pruned, deleted, erased, absorbed, rewritten, or disappeared over the years.
Over the years, I have deleted many projects that were shallow, flawed, useless, or otherwise uninteresting; I also stuffed sevag.io (and later sevag.xyz) to the gills with blog posts that I didn't really care about, that I wound up deleting eventually. I found blogging to be a poor platform; a "trust what I can talk about doing," rather than "look at what I've built" (as in standalone, successful GitHub projects). However, at some point I stopped deleting/regretting my work, to build an actual portfolio over a sustained period of time.
I'm not sure if ~36 projects over 7 years counts as prolific, but I certainly have written a lot of code. At the time of writing this blog post, my activity has wound down tremendously (aside from my open-source job). I thought I'd write myself a nice sendoff, and try to summarize the effort that I've put into my portfolio for a significant period of my life; 23.333% of it so far.
2015: the beginning
Pitcha
My first project was Pitcha, a pitch detection app for Android phones:

It had a simple UI that displays the note name (and octave) from the pitch detected from the realtime input stream of audio from the microphone, using the McLeod Pitch Method, or MPM. The note names are found by looking for the closest note to the detected pitch (within 1.2 Hz) from arrays of hardcoded values:
private static String[] noteNames = {"C", "C#", "D", "Eb", "E", "F", "F#", "G", "G#", "A", "Bb", "B"};
private static double[] oct0 = {16.35, 17.32, 18.35, 19.45, 20.60, 21.83, 23.12, 24.50, 25.96, 27.50, 29.14, 30.87};
private static double[] oct1 = {32.70, 34.65, 36.71, 38.89, 41.20, 43.65, 46.25, 49, 51.91, 55, 58.27, 61.74};
private static double[] oct2 = {65.41, 69.30, 73.42, 77.78, 82.41, 87.31, 92.50, 98, 103.8, 110, 116.5, 123.5};
private static double[] oct3 = {130.8, 138.6, 146.8, 155.6, 164.8, 174.6, 185.0, 196, 207.7, 220, 233.1, 246.9};
private static double[] oct4 = {261.6, 277.2, 293.7, 311.1, 329.6, 349.2, 370, 392, 415.3, 440, 466.2, 493.9};
private static double[] oct5 = {523.3, 554.4, 587.3, 622.3, 659.3, 698.5, 740, 784, 830.6, 880, 932.3, 987.8};
private static double[] oct6 = {1047, 1109, 1175, 1245, 1319, 1397, 1480, 1568, 1661, 1760, 1865, 1976};
private static double[] oct7 = {2093, 2217, 2349, 2489, 2637, 2794, 2960, 3136, 3322, 3520, 3729, 3951};
private static double[] oct8 = {4186, 4435, 4699, 4978, 5274, 5588, 5920, 6272, 6645, 7040, 7459, 7902};
Pitch is the perceptual correlate of frequency. What that means is pitch is the sensation evoked by a waveform at a certain frequency when input into the auditory system of a human being. The pitch of a note is its fundamental frequency, or f0; also its lowest frequency. Most complex musical instruments have harmonics, which are integer multiples of the f0, giving them a richer sound than a simple sine wave. If you want to know more, a presentation I gave in grad school in 2021 on pitch has some good information.
I began this journey with a confused question about pitch detection on the DSP stackexchange, which led to autocorrelation and the algorithm I would ultimately end up using: the McLeod Pitch Method (MPM). I recall originally copying the Java code from the TarsosDSP project. At one point, I incorporated a C++ implementation of code from my next project, a standalone collection of pitch detection algorithms written in C++.
In 2017, I made my last commit to the project, related to me switching my personal domain from sevag.io to sevag.xyz (I detest URL-based code organization; com.fuck.your.self.Please, it's soooo fucking ugly). My last commit also included the deprecation/EOL warning. In the end, I had difficulty finding the original publish keys I used on the Google Play Store, and I had absolutely no intention of re-releasing the code every time Google changed its permission models or whatever (seemingly every 2 weeks, from the emails I get as an Android user). As a result, my last release added some signed APKs directly in the repo.
The origin of Pitcha was my first work assignment. I had to write code that tested the audio input and output jacks of a Pandaboard. I was pointed to the Goertzel algorithm, and more specifically, an internal C implementation of the Goertzel algorithm written by a coworker. The Goertzel algorithm allows us to compute a specific term, or frequency component, of the DFT; you would use it if you know what frequency you're looking for in the input signal. It's relevant in Dual-Tone Multi-Frequency (DTMF) for dialing numbers in a telephone pad. I chose a frequency, created a sine wave of that frequency, emitted it from the output jack, received it in the input jack (with a 3.5mm male-to-male loopback connector), and measured the energy of the audio signal received from the input buffer, making sure that the energy of the input signal was maximal at the same frequency that I sent out using the Goertzel algorithm. I wrote it in C, using low-level ALSA functions on a custom BusyBox Linux image I compiled using Buildroot.
After Pitcha, I wanted something cooler than Java, so obviously I went to C++. I couldn't tell you when or why I made the language choice; it might have been related to discovering that a lot of the open-source audio ecosystem is written in C++.
pitch-detection
My next project was pitch-detection, a collection of O(N logN) pitch detection algorithms in C++. The intention was to isolate the pitch tracking part of Pitcha in a library, and have Pitcha only become a wrapper with a UI and note display.
At this point I had started to think of myself as Robin Hood, "democratizing" music programming by writing reference implementations of audio and music algorithms and papers. In my imagination, I was the common man, the every day man, not a brilliant programmer by any stretch of the imagination, which I assumed would add a sort of artisanal, handcrafted charm to my clumsy projects. No longer would a person say, "damn this ISMIR or DAFx paper is awesome, but where can I see a working example of it?" They'd just visit sevagh's* software emporium.
*: Small nit: sevag is my first name and h is my last initial, but sevagh is my GitHub username and my primary online persona
If you would like more of a background on different pitch tracking algorithms, I point you again to my 2021 grad school presentation on pitch detection, where I talk about autocorrelation, MPM, YIN, and other algorithms, most of which are found in my pitch-detection project.
In the beginning, there was only MPM. I added the Goertzel algorithm, which is questionable as a pitch tracker. Recall that the Goertzel algorithm allows you to compute the energy of a single frequency component. To detect pitch, one has to check the Goertzel energy of every single possible frequency, and choose the largest one; and indeed, that is what I implemented.
In 2016, I incorporated the YIN algorithm.
In 2017, a rather big mistake (passing the audio arrays by value, not by reference, causing the audio data to be copied unnecessarily) was corrected by one of my first contributors on GitHub. This is a good reason why C++ can be dangerous in the hands of the inexperienced or incurious. However, I am reckless, so I continued writing C++ for many future projects.
In 2018, I was able to write a YIN-FFT implementation successfully, which was a proud moment for me, because I had to create it from scratch. Up until that point, all of my signal processing code was ultimately copy-pasted from other working code, and simply morphed in different ways; none of it was an achievement or novel contribution. YIN and MPM also share the same underlying autocorrelation code, which helped me understand how they are variants of "autocorrelation with adjustments," as can be seen in this slide from the presentation I linked:
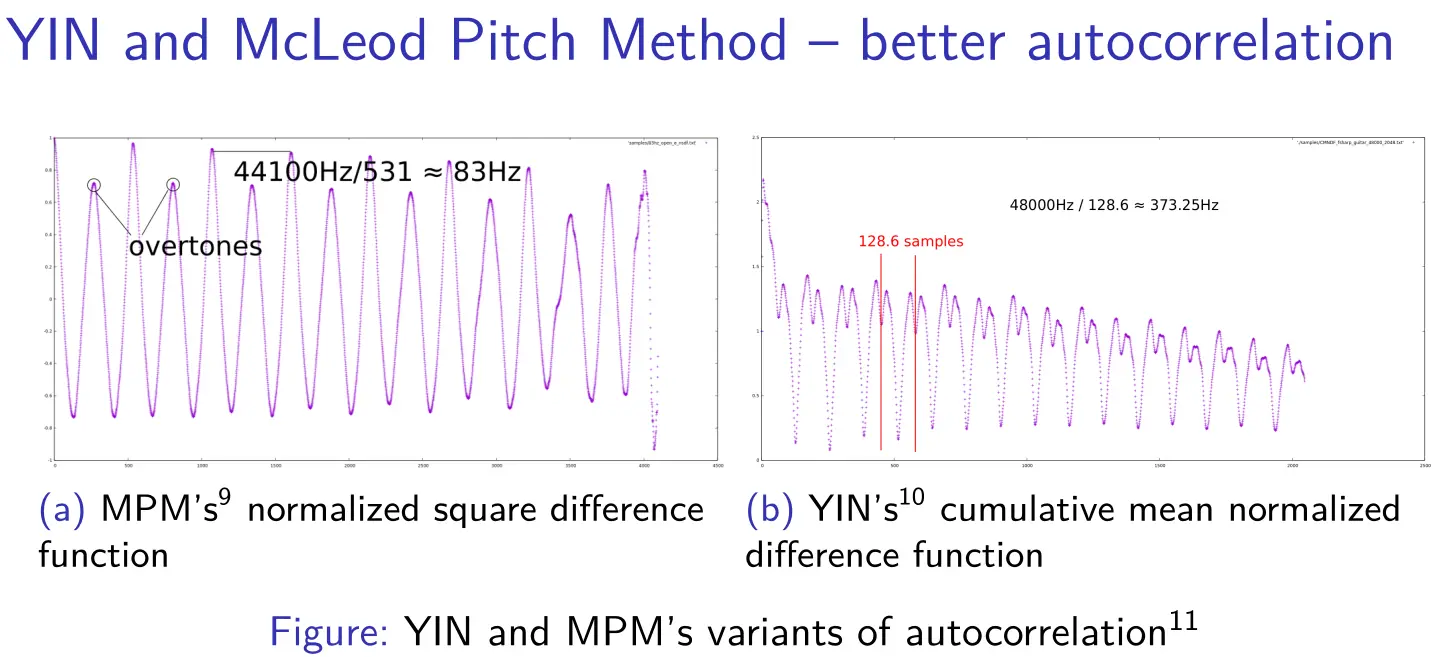
In 2019, I added probabilistic YIN (or pYIN), considered one of the best pure-DSP algorithms for pitch detection. I also added SWIPE and probabilistic MPM (pMPM), which is my own invention inspired by pYIN. At the time, I strongly believed pMPM deserved to be published; if pYIN is published, why not pMPM? But I had no idea how to get that done. I also added degraded audio tests showing how degenerate conditions of noise or distortion can affect the results of the different algorithms. This used a standalone project of mine, the audio-degradation-toolbox, which will come up later on.
My favorite part of this project was giving my first talk on the MPM in public about pitch detection as part of the Montreal chapter of Papers We Love, hosted by my friend in 2019. This talk gave me a mini-crisis since I was unable to answer a lot of the questions the audience asked me; in essence, I had stitched together a bunch of things (FFTs, autocorrelation, etc.) without really understanding them. The spark of wanting to do a master's degree must have been ignited somewhere around this time, to gain a more formal theoretical background on these fundamentals.
2017
2017 projects are split into Rust and non-Rust sections, because I wrote too much Rust that year  .
.
pq, surge, wireshark-dissector-rs (Rust)
First up is pq, my first Rust project, and one of my favorite projects to showcase my skills even today. It is unrelated to music or audio; it's a Linux command-line protobuf parser written in Rust:
$ pq --protofile ./tests/protos/dog.proto --msgtype com.example.dog.Dog <./tests/samples/dog
{
"breed": "gsd",
"age": 3,
"temperament": "excited"
}
In late 2016, I joined a company full of excellent software engineers and computer scientists who were passionate about open-source code and high-performance systems programming. We had an internal tool called pq (protobuf query), written in C++, which was the protobuf equivalent of jq (json query). It was abandonware that couldn't be compiled, but we actually needed a protobuf pretty-printing tool at the time for a large internal project. We had a day-long hackathon at the company, around the time that Rust was super hype; I believe everybody wrote a Rust project that day. I sat down and intended to re-write pq in Rust; here's the first commit.
What I recall about this project is that this is the one that expanded my brain, in the most painful and rewarding ways. It was difficult, I was extremely frustrated that at the end of an 8-hour workday I had nothing substantial at all, and I was told by one of the senior developers that coding is not easy and to stop whining like a baby and put in the work. For the first time, I couldn't copy-paste my way out of a problem, and had to sit down and carve it out of my own brain. I still maintain to this day that the lessons learned while writing pq were the most valuable to my career.
It has 7 contributors total up until 2021, adding a variety of features including performance enhancements (that I don't have the skills to have optimized on my own), Windows build instructions, incorporating updates to the Rust language, and more.
The company used to be called Adgear, and they let me retain all permissions and ownership of the code, even though I wrote a lot of it on company time. In fact, they did that several times, for every project I released in 2017 while I worked there  .
.
Continuing the Rust-mania, surge is a Rust command-line YouTube-based music player I wrote that used mpv and youtube-dl. My favorite trick was displaying album art using termimage:
More Rust led to wireshark-dissector-rs, a packet dissector for a small toy encoding scheme I invented, showing how one could use Rust code to define a network protocol, and use the same code in the server code, client code, and in a custom Wireshark dissector. Dissectors are a way you can create a plugin for Wireshark to be able to analyze custom network traffic:

This was actually a tiny proof-of-concept for a work task I didn't even feel like completing and abandoned. Still got a lot of attention (I do remember deleting and recreating it at some point, during one of my episodes of self-doubt).
goat, cholesky, transcribe, konfiscator (non-Rust)
goat kicks off the non-Rust projects of 2017. The name is from "Go-At[tach]" because it's written in the Go language and manages attachments of EBS volumes to EC2 instances in AWS. It used to be called Kraken, and I had an awesome logo for it:

Still at Adgear, we were deploying on AWS for the first time. I was using Terraform to create EC2 instances and EBS volumes, but had no way of dynamically attaching them to each other. goat is a tool that runs on Linux EC2 instance, looks for the EBS volume intended to be attached to that instance, attaches the volume, then sets up the file system, mounts, entry in fstab, etc. Everything is dynamically configured from the tag metadata attached to the instances and volumes. This was another fairly popular project of mine, and there is a more up-to-date fork maintained by a cloud consultancy company in the UK.
To present at one of our regular work tech talks, I wrote cholesky, a set of property tests for the Cholesky matrix decomposition algorithm in Python using Hypothesis. The aim was to show that we could use Python to test C (or Rust) code, by testing different implementations of the algorithm. Interesting to note here that the README is a .txt file, which is probably explained by me trying to be edgy. Other than that, the project is unremarkable.
Next, transcribe pretends to be a music transcriber; that is to say, you input raw audio and get sheet music (I lazily plotted them with matplotlib, not sheet music; I took a quick look at Lilypond and decided, no):
![]()
I remember trying to improve this project by adding some other content to shore up how thin this project was, with some profiling, performance optimizations, and Python packaging in a single binary.
Finally, konfiscator started off badly; the name is intended to be the inverse of being allocated memory, or memory being confiscated. I tried to create a custom implementation of malloc using Rust vectors (Reddit pointed out the flaws of this when I posted it). In 2020, I reworked it entirely to copy a working C malloc implementation using the first-fit free list algorithm, and some kernel features to record Prometheus metrics for malloc stats and a Python exporter for Prometheus to read the stats and publish them as metrics. No more Rust. I'm proud of the makeover; the first version was lazy garbage. 2020 reflects when I started being more comfortable with Linux internals after working as a Site Reliability Engineer (SRE) at Pandora (Oakland-based music streaming company, not jewellery) for several years.
2018
2018 was a slower year. It was my first year at Pandora, and I lived in Oakland for the majority of it. When I moved back home to Montreal, I worked on two projects.
top-bar-clocks was a simple Gnome extension to display the time from different timezones:
This was a fun project; it's my only Javascript project ever, and I had to follow the rules of Gnome extensions, giving it a different flavor from my typical open-ended audio/music project. I actually don't use the extension anymore.
CircularWSDeque is a circular work-stealing double-ended queue, which is my C++ implementation of a computer science data structure intended for concurrent access from workers, from the paper. I worked on this to try to improve my computer science skills, at the time where I had mentors around me who were enthusiastic about reading new CS papers on algorithms or data structures and implementing them yourself from scratch, and I wanted to try my hand at the same sort of thing. As I've mentioned before, I wouldn't trust this project, as it most likely suffers from my dangerously deficient C++ skills.
2019
orgmode, thesis, and content calendar
Over the years, I had many fledgling starts at "this time I'm going to get good at computer science/operating system fundamentals." I would practice a lot of programming puzzles like Leetcode, Project Euler, Advent of Code among others. I would also read computer science textbooks, like Skiena's Algorithm Design Manual or CLRS, and write my own implementations of algorithms and data structures from scratch; in essence trying to create my own "STL" multiple times (the name of the C++ standard library full of high-quality, standardized implementations of computer science algorithms, data structures, and containers).
My interest in these things were twofold:
- A social group I shared with a bunch of ex-coworkers who lived and breathed code. To them, every day is about furthering one's understanding of fundamental algorithms and data structures
- Greed, by improving my skills enough to pass intense job interviews for high-paying positions
My strategy was a mix of being genuinely curious and feigning genuine curiosity to mask my naked greed, to avoid being transparently uncomfortable at the job interview (like somebody who was nervous and faking their knowledge). It's a fine line. Every year that I did a small interview grind, it never lasted long enough. I would run out of endurance to keep learning difficult material, or get demoralized soon after a rejection.
In 2019, all of this changed. I decided that I would harden my approach into a process where I wouldn't stop until I got results. This is probably when I became most convinced that a master's degree was the right move, because around the time I would be running out of the steam in my own internal engine of motivation, the external process of the degree would continue forcing me to release projects. That way, I could make sustained long-term progress and achieve goals, rather than giving up within a few short weeks or months.
The first content calendar commit was created on June of 2019, after a period of exasperation at my projects:
* TODO No shame in reinstating sevag.xyz, patient, slower projects
** quadruple focus on MIR/music education
*** JOB DESCRIPTION TIPS:
**** C++, DSP, Advanced Mathematics, Wwise, FMOD (audio/game audio middleware), Crytek/Unreal/Source/Unity audio
** projects
*** Polyrhythm?
*** STFT, onset detection
*** something with webcam and audio
**** tiny webcam drum-kit
**** clapping bpm visualization
** blog posts
*** the effects of windowing functions on pitch detection
** word map/dictionary/glossary of music/audio engineering?
*** CS theory
In hindsight, it's cool to see how the above list came to life in subsequent projects:
- Polyrhythm: libmetro, headbang.py
- Onset detection: headbang.py
- Webcam/audio, clapping bpm visualization: headbang.py
- Effects of windowing functions on pitch detection: actually the seed of xumx-sliCQ and my thesis
Shortly after, I added a list of topics in audio and MIR, seemingly for the "word map" project above:
** topics:
*** DSP basics
**** continuous time vs discrete time signals
**** time domain vs frequency domain
**** FFT
*** Related projects
**** Introduction to the audio-degradation-toolbox
**** pitch-detection
*** Pitch detection
**** Autocorrelation
**** MPM
**** YIN
**** pYIN
**** window functions
*** Beats and rhythm
**** Onset detection
***** STFT
**** Tempo
*** Source separation
Finally, it turned into this; a series of tags to keep score of my progress:
-*** JOB DESCRIPTION TIPS:
-**** C++, DSP, Advanced Mathematics, Wwise, FMOD (audio/game audio middleware), Crytek/Unreal/Source/Unity audio
-**** Experience with Audio stack like codecs, audio capture/render, jitter buffer and signal processing.
-** word map/dictionary/glossary of music/audio engineering?
-*** include CS theory in this
-
-* TODO Find a solution for CS theory + leetcode proficiency
+**** [TOPIC A, 1] Expertise in developing advanced Audio and Speech Processing Algorithms
+**** [TOPIC B, 1] C++, DSP, Advanced Mathematics
+**** [TOPIC C, 1] Experience with Audio stack like codecs, audio capture/render, jitter buffer and signal processing.
+**** [TOPIC D, ] C/C++ multi-threaded
+**** [TOPIC E, 1] Knowledge of digital signal processing theory (FIR/IIR filter design, adaptive filtering, frequency domain
+analysis).
+**** [TOPIC F, ] real-time communications technologies (VoIP or media streaming) Audio/Video encoding/decoding/trans-coding,
+ Video/Audio compression, WebRTC, RTP, RTCP, SIP, etc.
+**** [TOPIC G, ] Experience with Audio software stack in different platforms (Windows, MacOS, iOS, Android, Linux)
+**** [TOPIC H, ] Experience with AECs, AGC, Noise Suppression, etc.
+**** [TOPIC I, 1] Experience with machine learning for Signal Processing
+**** [TOPIC J, ] Experience with Audio tools and quality standards - POLQA, PESQ, ERLE
+**** [TOPIC K, ] Wwise, FMOD (audio/game audio middleware), Crytek/Unreal/Source/Unity audio
+**** [TOPIC X, ] Music theory
+**** [TOPIC Y, ] systems/SRE/perf
+**** [TOPIC Z, ] CS theory, leetcode/puzzles
Also, I was making heavy use of orgmode to track progress during the execution of a project, which I still do; notes, TODOs, subtasks, what's blocked on what, etc. For example, this some of my orgmode tracking for my project ape (will be discussed soon):
* TODO ape
*** socat test bench is good
*** UDP for now is a good constraint
*** TODO add port-specific code
https://github.com/google/packetdrill/blob/master/gtests/net/packetdrill/packet_parser.c
**** TODO add port to metrics, comma-separated ports to create duplicate blocks in xdp_prog
*** TODO scramble function unlocks jitters
**** TODO need XDP_REDIRECT - AF_XDP for scramble
https://www.kernel.org/doc/html/v4.18/networking/af_xdp.html
https://lwn.net/Articles/750845/
*** TODO mirror function is the whole point of ape - that comes laaater
**** TODO AF_XDP/scramble will lead to mirror
devices, ports
DOCKER AND APE: https://medium.com/@fntlnz/load-xdp-programs-using-the-ip-iproute2-command-502043898263
These are just excerpts; my style was pretty messy and disorganized, but over time I've been consistent and I can generally use the tools and skills at my disposal to get things done.
CS and Linux systems projects
In 2019 I'll split my projects into two categories: projects that focused on concepts in computer science and the Linux operating system, which were more about improving my skills for employment purposes, and more creative projects from the audio and music track. This section will contain the CS and Linux OS projects.
I started the year off with quadtree-compression; I took an interesting data structure, the quadtree, and created an image compression algorithm based on it. My favorite part is the animated gif showing how it works (generated with a command-line gif tool in the project):

Next, to focus on Linux concepts, I worked on ape in conjunction with jitters.
Jitters is a from-scratch, Rust implementation of RTP, a realtime audio protocol. The Linux/OS concepts I intended to learn were networking-oriented (even though there is a realtime audio aspect to the project). The name comes from "jitter-rs," where "-rs" is Rust, and "jitter" is the jitter buffer, a concept in RTP that allows for correcting out-of-order packets that would scramble or distort the audio.
Ape is an accompanying project to jitters, where I used a Linux networking feature called XDP, or eXpress Data Path, based on eBPF (extended Berkeley Packet Filters), to manipulate network packets and test different aspects from my RTP jitter correction algorithms in jitters. The name "ape" comes from mirroring or aping packets.
I released namespace-experiments, a partially-completed project where I tried to use Linux namespaces, which are the basic building block of more advanced container platforms like Docker. My intent was to create an isolated namespace in which sudoers permissions could be simulated, to detect issues with security privilege such as transitive escalations, etc.
After these, I worked on a multitude of data structure projects in quick succession:
- k-ary-tree, a Go library to recursively represent any k- or n-ary tree (including binary trees, quadtrees, etc.)
--- | a | --- / / firstChild / --- --- --- | b | ---------- | c | -- | d | --- nextSib --- --- | | | | firstChild | firstChild | | --- --- --- | g | | e | --- | f | --- --- --- - red-black-tree, a Rust implementation of the red-black tree data structure, using unsafe raw pointers and a slab allocator
- ringworm, two Go implementations of ring buffer (or circular buffer) data structures with comprehensive testing
- splashmap, a Rust implementation of a hash map with a splay tree data structure for collision chaining (splay trees are my favorite) with some memory usage benchmarks
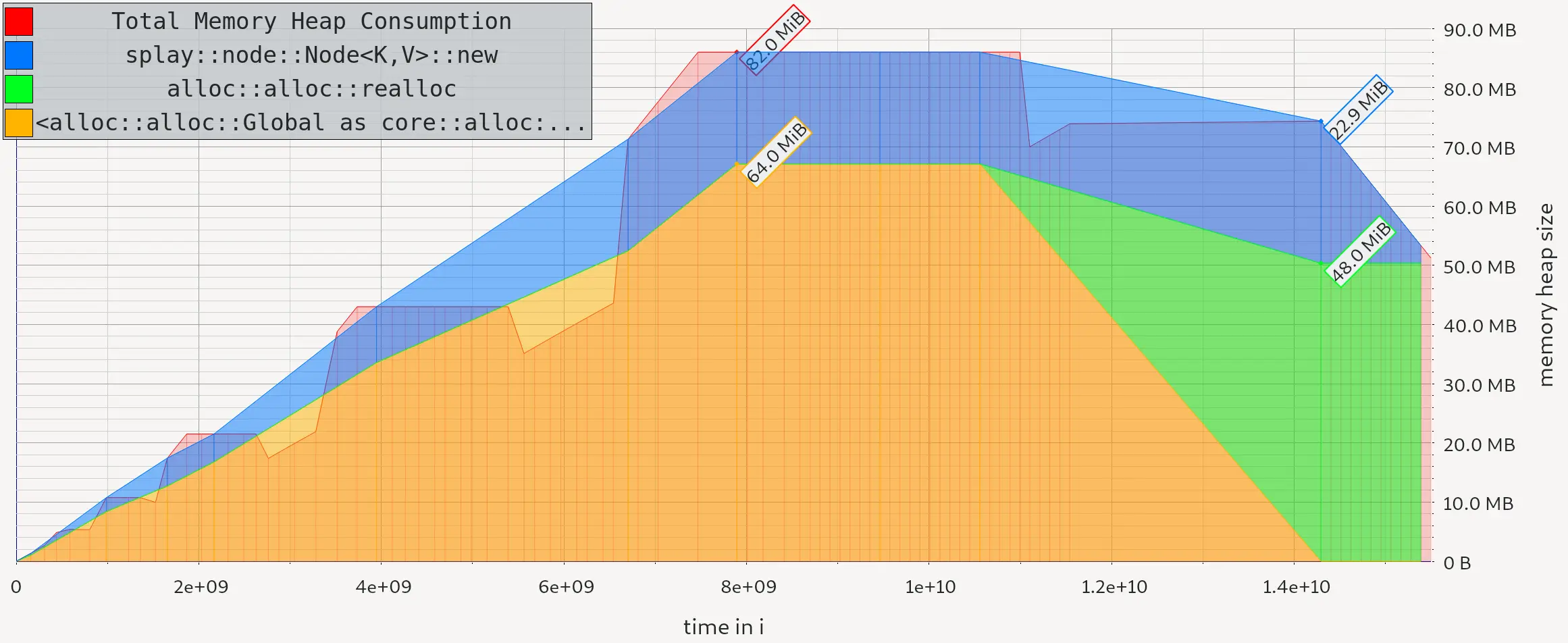
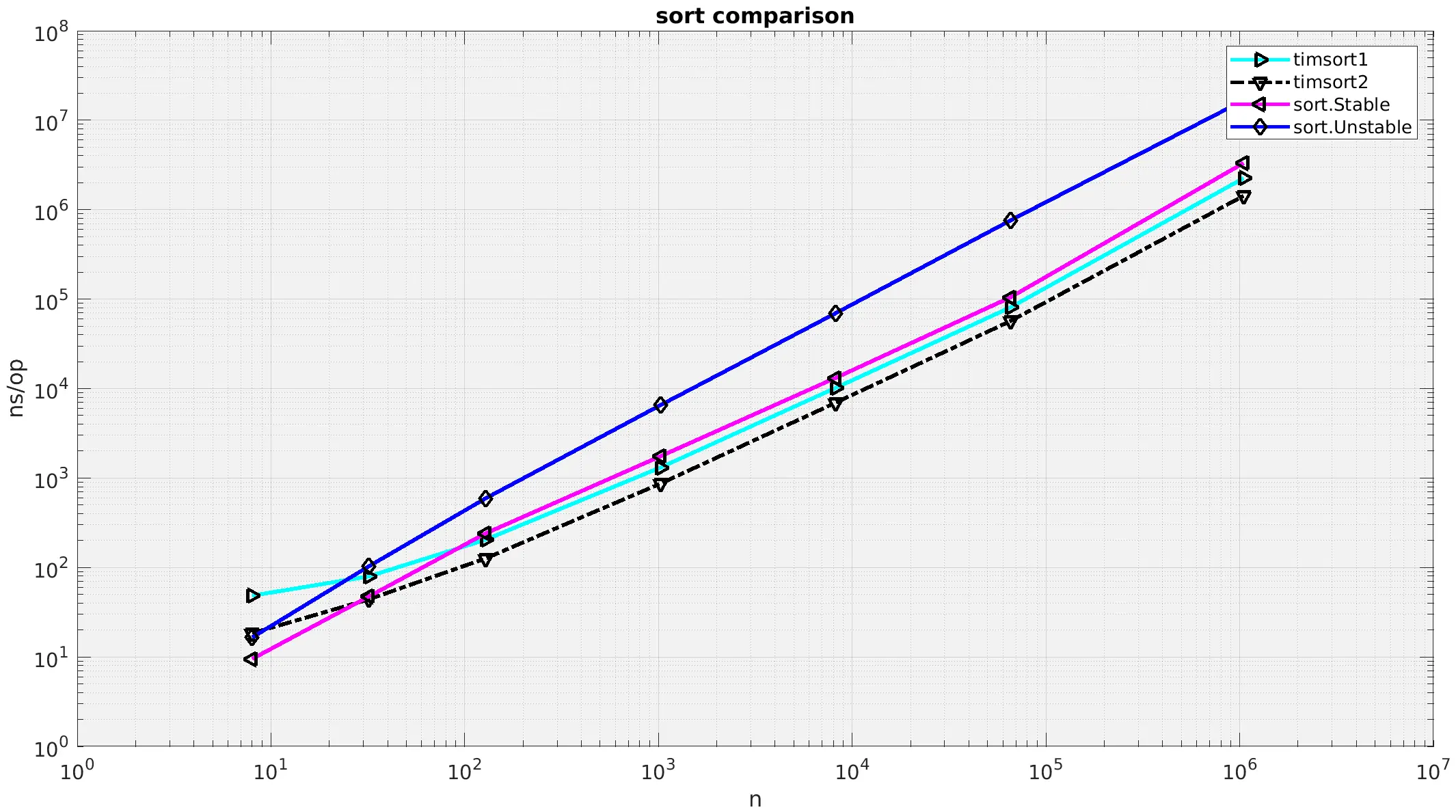
- go-sort, a collection of sorting algorithms written in Go with the intent of learning different sort strategies, based on some of the Go standard library's sorting functions; most impressive here is that I actually hand-wrote two implementations of Python's TimSort that outperformed the Go standard library sort functions (inspired by Orson Peters' pdqsort)
- Scriptorium, which is a webcam-based reading assistant that uses OCR (optimal character recognition) and the DAWG data structure (directed acyclic word graph) to create a local translation dictionary as a foreign language reading assistant using multiprocessing:
Music and audio projects
This section will cover the music and audio projects of 2019; it's also when I started doing coursework for my master's degree.
Released in the spring of 2019, audio-degradation-toolbox is a Python tool to perform various manipulations and degradations to audio, to simulate real-world sound quality issues. It's my own Python and JSON-based implementation of the various audio degradation toolboxes published to ISMIR. I used this in my pitch-detection project to show which algorithms perform better under degraded audio conditions.
In the summer of 2019, I released chord-detection, a collection of algorithms for chord (and key) detection based on signal processing algorithms, with visualizations of the intermediate steps of the algorithms, to fully illustrate the algorithms proposed by the original papers:
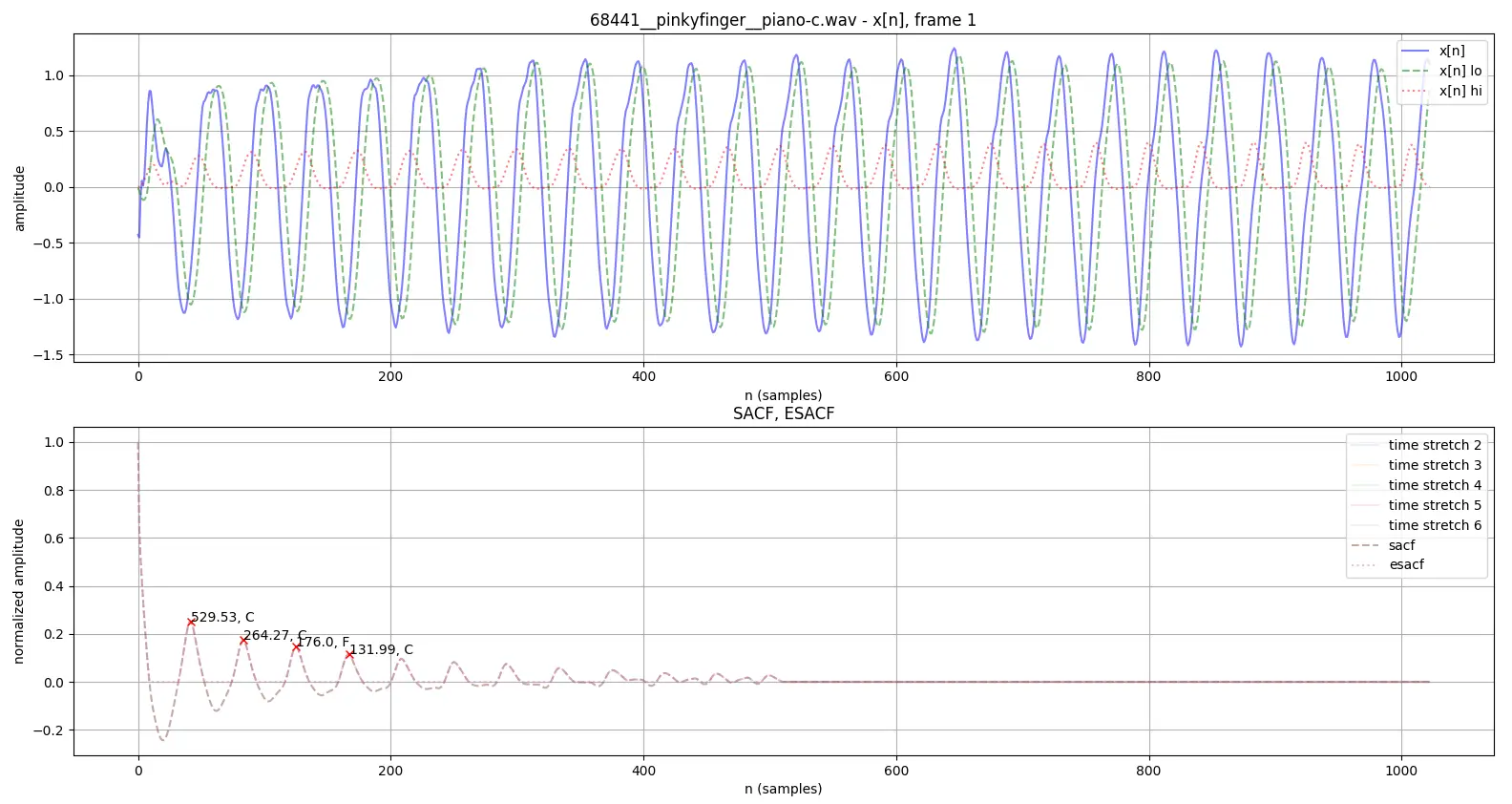
I'm surprised at how popular this project became (58 stars when I wrote this blog post). It was intended to be like my collection of C++ pitch detection algorithms, except with Python to make my life easier and rely on bigger, established projects.
In the same summer, I worked on warped-linear-prediction, an interesting topic that actually lasted through to my thesis research. It's based on the warping of linear, uniform time-frequency analysis to be more nonuniform or uneven, in ways that map more to real music or the real human auditory system; higher frequency resolution at low frequencies, and higher time resolution at high frequencies. I tried to document my building process in a website. I used warped frequency to ultimately create an audio codec like FLAC:
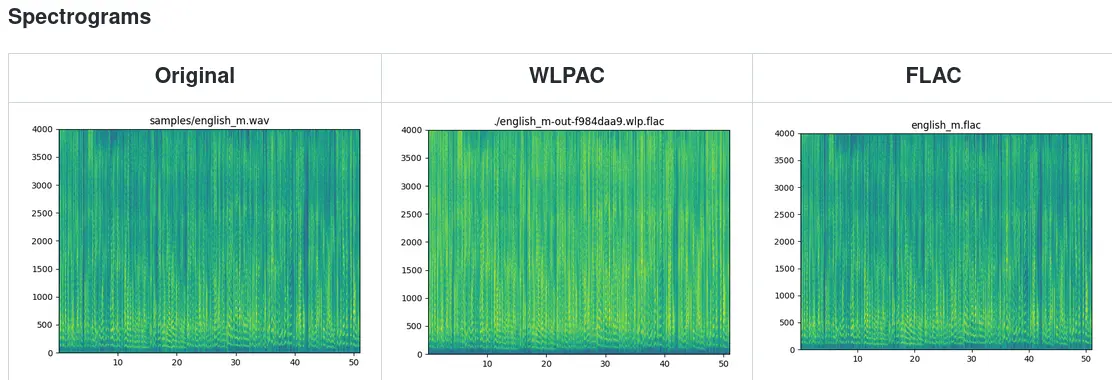
As a mini-project, I introduced Rust bindings to ffts, my fork of the Fastest Fourier Transform in the South (another one I deleted and then recreated from the crates.io tarball).
Finally, libmetro was a project I delivered as my first final projects for the first course I took in the music technology department related to my master's degree, and my first time back in school since graduating in 2014. It's a C++-based library using libsoundio and the Synthesis Toolkit. Libmetro is a library (and set of command-line tools) for creating a synthetic, looping metronome-like series of clicks (with different timbres) to represent a given time signature:
#include "libmetro.h"
int bpm = 100;
auto metronome = metro::Metronome(bpm);
auto downbeat = metro::Note(metro::Note::Timbre::Sine, 540.0, 100.0);
auto weakbeat = metro::Note(metro::Note::Timbre::Sine, 350.0, 50.0);
auto mediumbeat = metro::Note(metro::Note::Timbre::Sine, 440.0, 65.0);
metro::Measure accented_44(4);
accented_44[0] = downbeat;
accented_44[1] = weakbeat;
accented_44[2] = mediumbeat;
accented_44[3] = weakbeat;
metronome.add_measure(accented_44);
metronome.start_and_loop();
I focused on trying to learn what polyrhythms are (and other musical terms like measures, notes, down beats, weak beats, off beats), and also produced a comprehensive documentation website as the final deliverable.
2020
Starting from 2020, my projects became a lot more academic-focused. I really entered the stream of my music technology degree, and started tackling projects I had been thinking about but unable or unwilling to execute for a long time, such as source separation.
School projects
I worked on ElectroPARTYogram, an Android app for rendering an animation driven by beat tracking applied to the input stream captured from the microphone (example video):
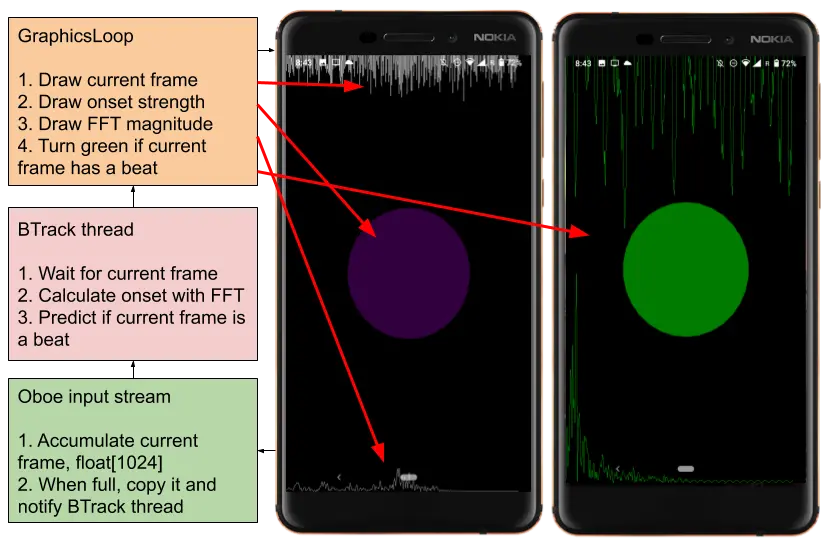
In Real-Time-HPSS, I wanted to apply realtime source separation to improve the beat tracking by separating or isolating the percussive component of the sound, to improve ElectroPARTYogram (although I did not incorporate both aspects in the same project). I was able to modify the Harmonic/Percussive Source Separation algorithm to work in realtime with a sliding STFT:
In prose2poetry, we worked on a Natural Language Processing (NLP) project to generate and evaluate poetry from prose texts:

In headbang.py, I took a look at my rich list of projects related to harmonic analysis (pitch, chords), and desired to publish the equivalent in the world of rhythm; beat tracking, onsets, percussion, time signatures, etc. This has one of my best websites documenting the process. The origin of headbang.py was to try to figure out what aspect of a metal song makes fans want to headbang. I came up with a consensus beat tracker with percussive onsets to detect heavy percussive hits and find out when a song really grooves:
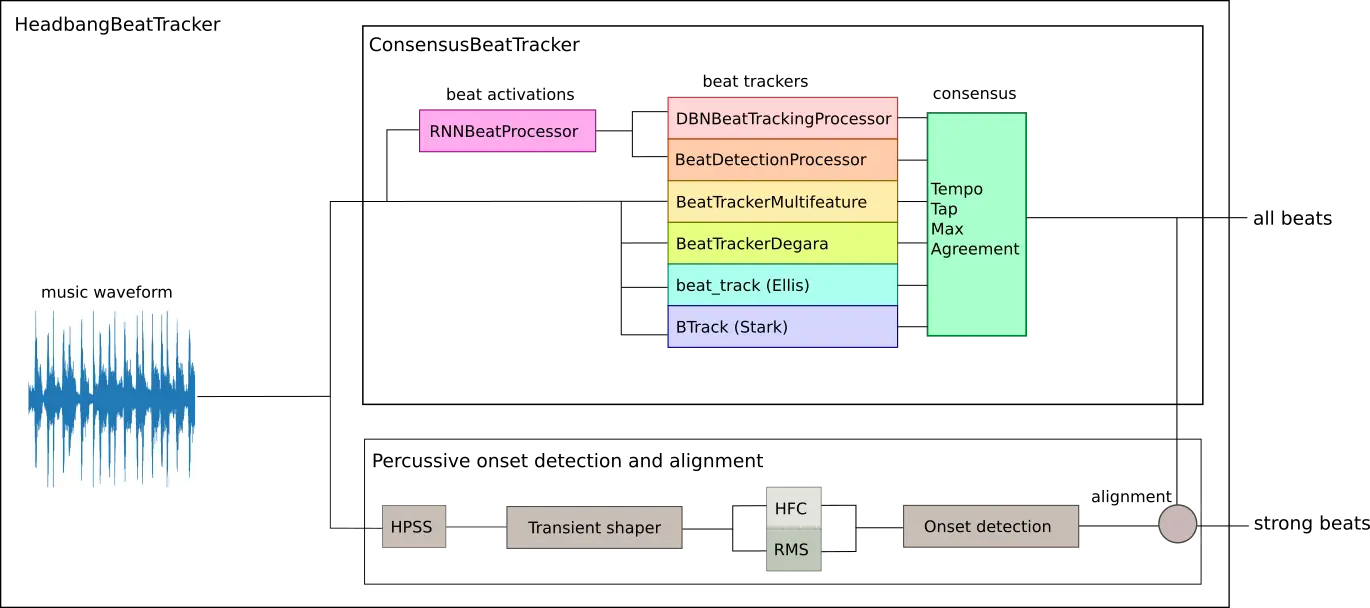
I also have two 2021 grad school presentations (1, 2) on beat tracking background if you're interested.
After the audio-only algorithms, I added a vision-related component where I tried to analyze repetitive motion of humans reacting to music (such as headbanging in metal concerts), using OpenPose for pose estimation:

This is when I started (and also stopped) being interested in beat tracking, when I got into the rabbit hole of the bizarre and unavailable data sets used for beat tracking training and evaluation in MIREX and ISMIR (more on this in the academic rant section later), and also when I couldn't really reconcile the fact that one beat could be described "correctly" with more than one time signature.
Here's an earlier version of the UI when I took the groove part more seriously:
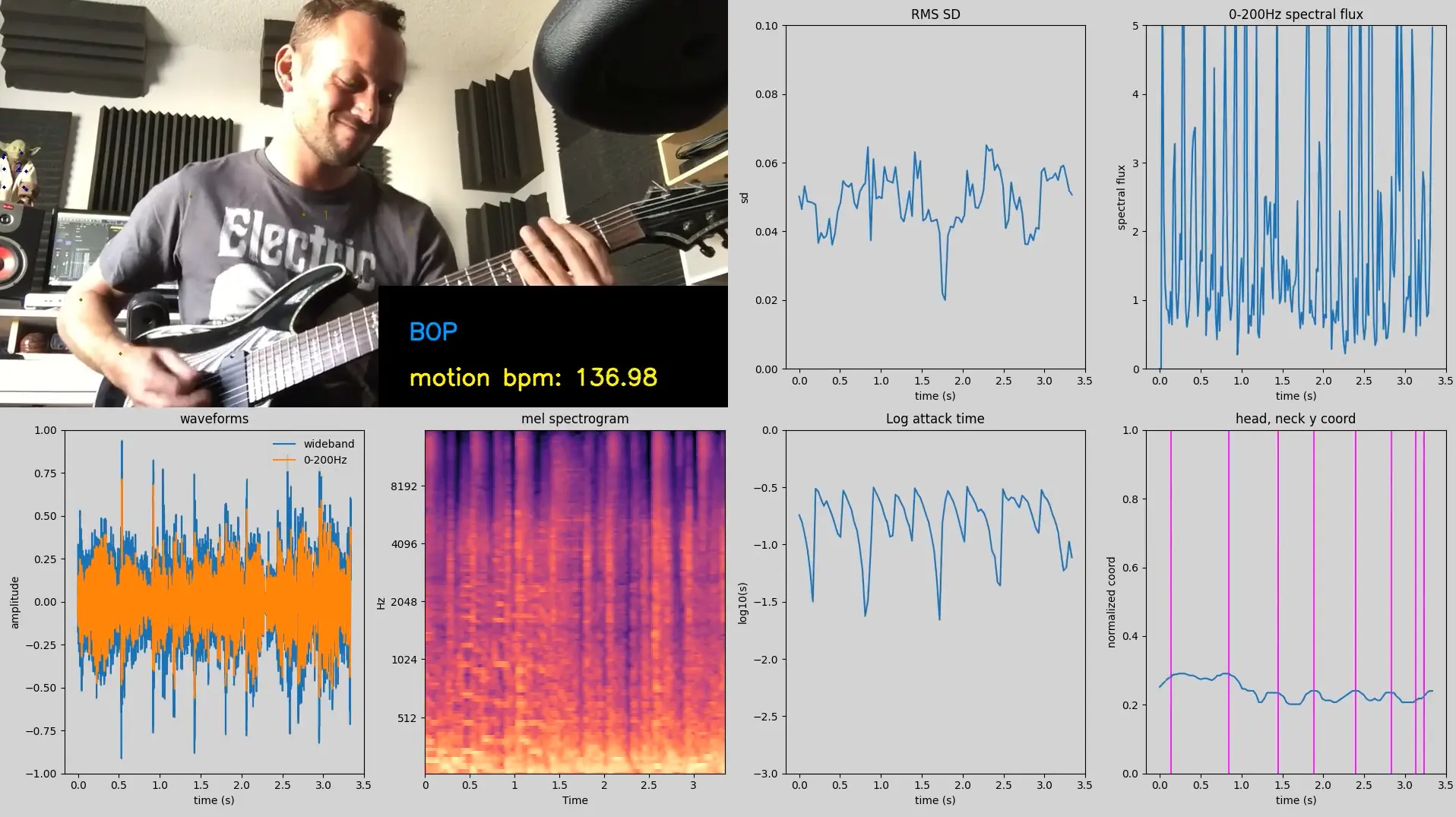
A fun fact about the pose estimation portion of the project is that I originally got the idea from a Brazilian jiu-jitsu friend who wanted to analyze jiu-jitsu matches with pose estimation. Here's an old photo I shared with him:
I also worked on 1000sharks.xyz, an AI-generated music artist (complete with a fake Soundcloud artist page), again with a detailed website on the construction of it:
In 1000sharks, I also absorbed some of my earliest neural network experiments in the tasks of source separation and transient enhancing to emphasize percussive drum hits. This is a small excerpt of how I share a lot of material between projects, and how I can chop up or absorb intermediate, incomplete steps across different projects (for example, 1000sharks and headbang.py share some roots from the neural drum experiments).
Non-school projects
I released a variety of projects that spun off from the above school projects, that weren't directly used as school deliverables.
One failed project was ditto, named after the TC Electronics Ditto looper pedal. The goal was to write a high-performance C++ magic ringbuffer to use in ElectroPARTYogram (I ended up just using a normal std::vector<float> for the beat tracking realtime audio buffer). Ditto is supposed to demonstrate faster throughput than a regular ringbuffer, but my version didn't even come close.
Another derivative project was drum_machine, based on libmetro (described above) and the Harmonix Set, which generated looping metronome tracks from the beat annotation files in the Harmonix Set.
Next was multiband-transient-shaper, software based on a mythical analog which I used in headbang.py to enhance percussive onsets, using Bark subband decomposition (in a nutshell, processing the audio in independent frequency buckets distributed according to the Bark psychoacoustic scale):
![]()
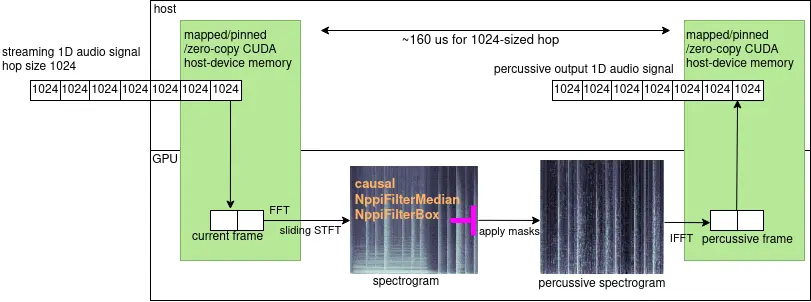
Zen is my best C++ (and CUDA) project to date. It's a collection of realtime and offline implementations of different harmonic/percussive source separation algorithms (inspired by Real-Time-HPSS, described above):
xnetwork, whose name is a play on the popular Python graph data structure library networkx, is a Rust graph data structure library using slotmaps. I wrote while I was learning about graphs.
With raft-badgerdb, I wanted to gain a passing familiarity with the Raft consensus algorithm and key-value stores, and killed two birds with one stone with a tiny mini-project.
2021
2020 seems to be the last year in which I worked on separate project streams for my music technology degree and personal open-source ideas. In 2021, I went all-in on schoolwork.
Non-thesis projects
For a more purely academic set of projects, I published MIR-presentations and TF-presentations, where I worked on various presentations I made in-class during my grad school seminars, on the topics of Music Information Retrieval (MIR) and Time-Frequency (TF).
I did more work on music source separation (continuing from Real-Time-HPSS), releasing Music-Separation-TF, a collection of different algorithms based on principles of the time-frequency uncertainty principle for music source separation, with extensive evaluations and visualizations of algorithm performance comparisons:
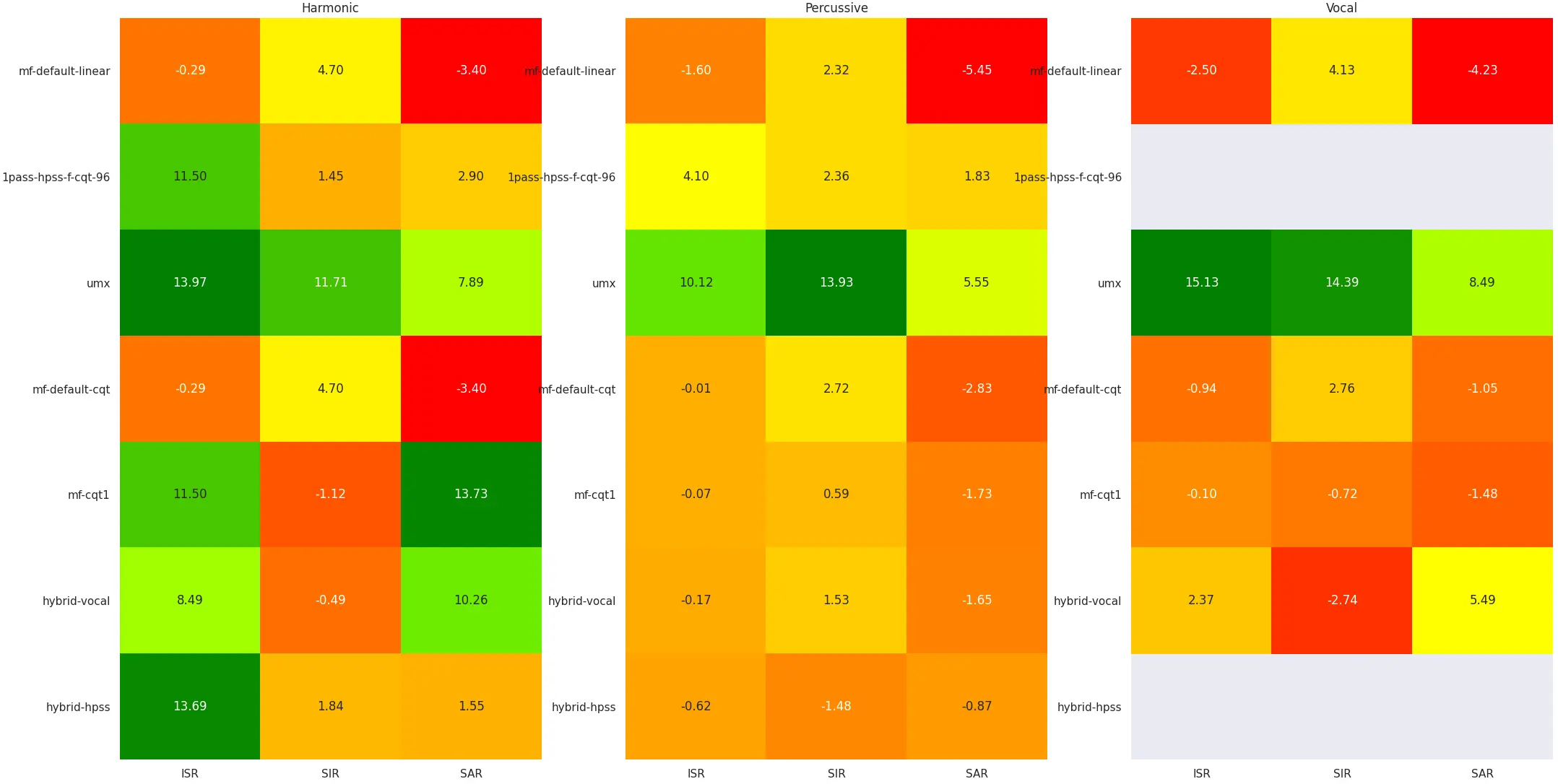
I also worked on MiXiN, a neural network for music source separation using the Nonstationary Gabor Transform:
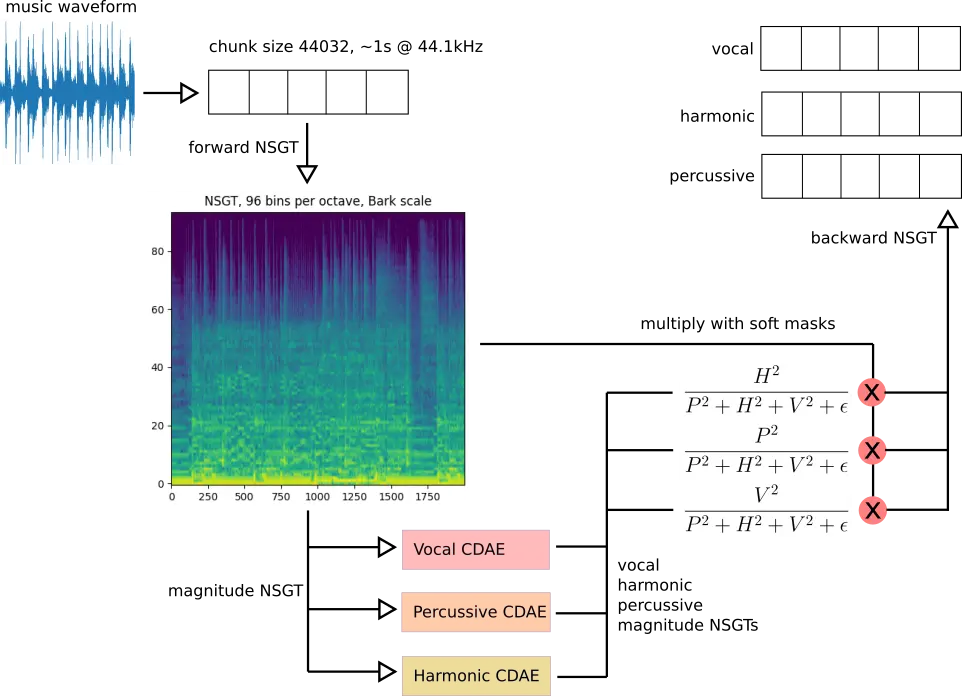
Both of these music source separation projects were for school, and these two projects foreshadowed my thesis project and the upcoming year of coding.
Thesis projects and the Music Demixing Challenge
In the summer of 2021, the first Music Demixing Challenge occurred on AICrowd. It was a competition where participants would try to write the best music demixing (or source separation) system, by either modifying existing baselines/starting points, or writing something entirely new.
I oriented my thesis goals with the MDX21 challenge, and decided to continue exploring time-frequency uncertainty in music source separation. In short: if we use spectrograms with the STFT (Short-Time Fourier Transform), we have to make a choice between having more frequency information or more temporal information; we must trade off knowledge of what notes are playing with knowledge of when the notes are played. This is a consequence of the window size of the STFT; a long signal is split into overlapping, consecutive windows in time to take a finite, frame-wise FFT of each window. If we consider short windows, we can detect events that occurred on the time scale of that window, but the window might not be long enough for the periodicity of a low-frequency note. If we consider long windows, we lose the temporal information of what notes were struck when, but we capture low frequencies with longer-duration wavelengths.
Nonlinear or nonuniform time-frequency transforms use different window sizes in different frequency regions, to suit the analogies of the human auditory system and Western music theory both (low frequencies give harmonic information, high frequencies give temporal information). The NSGT (Nonstationary Gabor Transform) and sliCQT (sliced Constant-Q Transform) are examples of nonlinear time-frequency transforms:
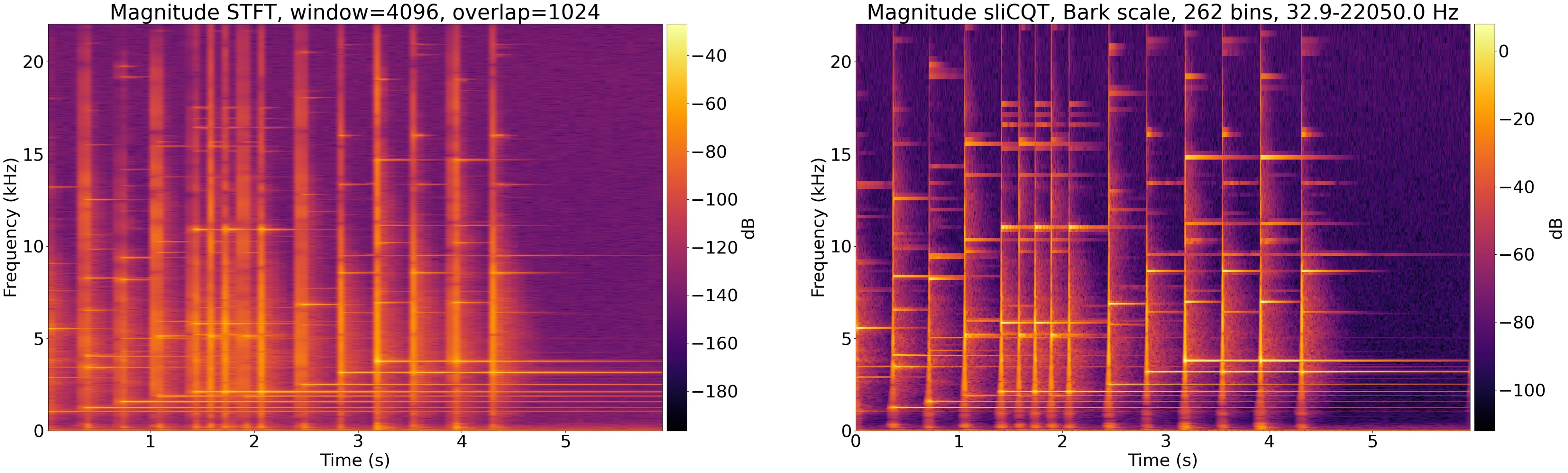
This is the complete list of projects related to my thesis track:
- nsgt, my fork of the reference Python implementation of the NSGT and sliCQT, where I added PyTorch support to use the transforms in a deep neural network
- mss-oracle-experiments, my first time poking around with the NSGT and music demixing
- music-demixing-challenge-starter-kit, where my code and model checkpoints were submitted as part of the MDX challenge
- sigsep-mus-eval, my fork of the BSS evaluation metrics for music source separation which I accelerated with CuPy and GPUs
- xumx-sliCQ, the code associated with my thesis project and final submission to the MDX21. I wrote a paper on it, which was accepted for publication in the ISMIR 2021 MDX workshop satellite conference (it's also on arXiv):
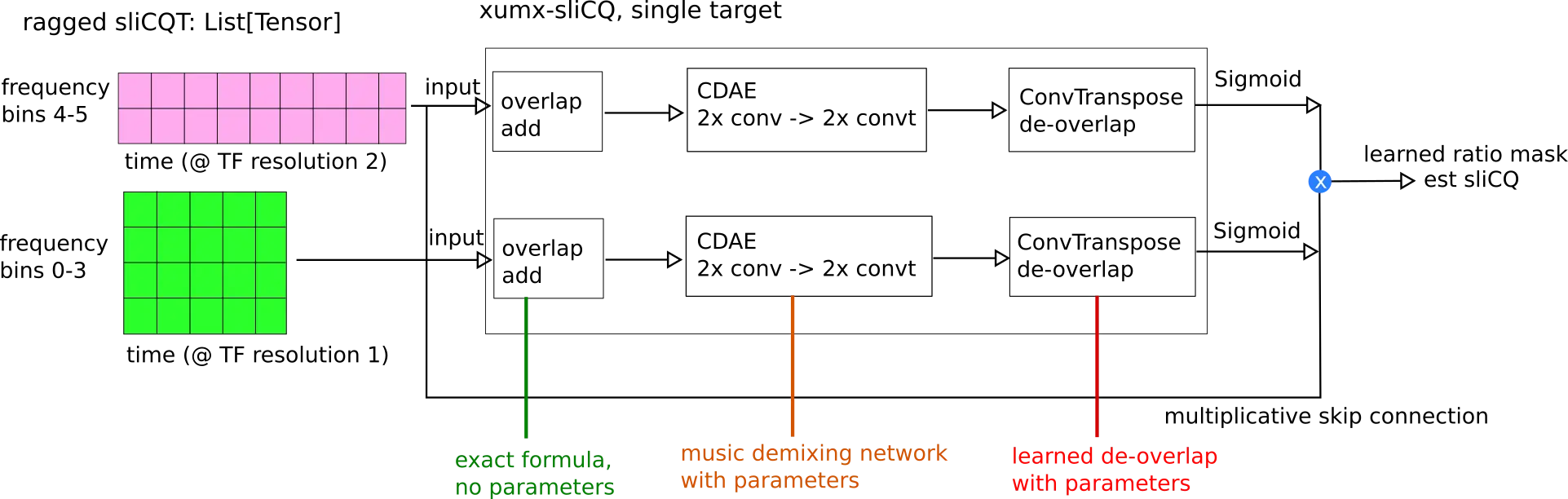
- xumx_slicq_extra, where I have the LaTeX code for my thesis, papers, presentations, posters, benchmarks, evaluations, and a whole lot of Bash and Python scripts to generate plots and different materials to accompany xumx-sliCQ
- The OnAir Music project, which consists of a dataset of stems from a royalty-free music project (I released this with my friend, the founder and musician behind OnAir Music) and onair-py, a Python loader library. These are intended for music demixing research, similar to the MUSDB18-HQ dataset and loader library
2022
In 2022, I continued working on xumx-sliCQ and my thesis, and stopped working on new open-source projects. You can read the first draft of my thesis here. I hope that my thesis gets accepted this year, that I get my master's degree, and continue on my merry way. I won't rule out a PhD yet, but after you read about my problems with academia below, it would be a strange twist if I changed my mind and decided to do even more schooling. Industry is infinitely better than academia.
In my personal life, I settled for a more private, local instance of Gitea on a home server to work on non-code projects, simply to keep my affairs organized, and I'd even like to tear down this modest infrastructure and go deeper into minimalism (hopefully by September 2022). I've been using Fedora as my distro of choice exclusively since 2013, and that hasn't changed, and likely won't ever.
2022 is when I'm no longer overtly interested in dramatic bouts of hard work or burning the candle.
Lessons learned from open-source
I wanted to spend years getting good at something. And I spent years but I'm not sure if I'm good. I explored as many corners of code projects that I had the endurance to, until at some point I realized I could keep releasing projects, ad finitum, without making more (significant) progress in the world of audio and music programming than I already have.
In terms of the pareto principle, I've long surpassed the 20% effort 80% results from my open-source portfolio; it can rest.
Open-source and my career
One of my favorite parts of my GitHub portfolio is how it benefits my career by just passively existing. It's helped me get hired at all of my jobs so far, and I also get reached out to with job offers on a pretty regular cadence. You may also be able to get that from other career websites, but I find people discovering me on GitHub are generally trying to be more of a "culture fit" with me in how we care about code; the leads are more organic or meaningful.
You often hear that since GitHub projects can be faked, employers don't really care about whatever you put on there; your time is better spent practicing for coding interviews. I'd rather work for people that can recognize my high-quality portfolio and how it represents my good qualities, vs. adversarial interviewers whose underlying attitude is that I am lying about and faking my entire career and life's work.
Throughout the day-to-day of my career, open-source has been prevalent as well. The 2017 section of this post contains projects that I developed almost exclusively at Adgear, a company I worked at. Open-source was part of the DNA, and it's a large part of why I published so many projects.
At a certain company, I created a Prometheus + Thanos metrics platform, intended to plug into the HashiStack (Consul, Nomad, Vault) and docker. I wrote a lot of high-performance, custom Go glue code for the disparate pieces of our internal platform. We weren't allowed to open-source any of it, despite being huge customers with legitimate business needs that deserved to be upstreamed, not simply patched internally. I'm still disappointed by that decision. We didn't even get out company logo on the Thanos.io "corporate customers" page, and we were maintaining an enormous (TB-scale) on-prem installation (built by yours truly).
Today, I'm a happy member of the NVIDIA RAPIDS team, who maintain a collection of open-source GPU data science libraries.
Monetization, licenses, and entitled users
I received many emails over the years; the vast majority of them about my pitch projects. One asked me if they have permission to use my GPL code in Pitcha to monetize their own smartphone app. I told them, "it's unlikely I'll try to find you and sue you, so do whatever you want." Basically, if they found ways to monetize that I didn't, it's a personal failing on my end.
I enrolled in the GitHub Sponsors program until I decided I don't really want to be on the hook for providing legitimate paid support for any of my code; it just exists as a reference, use at your own risk. Also, I didn't quickly make money like I expected.
Aside from job opportunities (which is a big benefit), I haven't made a cent off my open-source projects or portfolio. That's the lowest stress way I can commit to both having a strong portfolio to demonstrate my skills, without having the added stress of needing it to produce an income.
I use the MIT or BSD licenses most commonly, because I don't want anybody to hesitate when they copy-paste my code. I don't really care about attribution or fair use or any of those things. In a more abstract sense, if people are copy-pasting my code, it's because I'm simply part of the fabric of "exemplar music and audio code available in the wild," and so I am satisfied.
So many dumb things I see daily on whiny communities of effete diva babies:
- tl;dr if you're not prepared for your code to be used like toilet paper, by toilet paper, with as much respect as toilet paper, don't put it on GitHub.
- I have responded unhelpfully to many stupid GitHub issues over the years. I suggest you do the same. Don't be so nice that it causes you distress. I've also received a lot of unhelpful and unpleasant communication from other open-source maintainers. Just lower yourself to the expected level of discourse, and you'll be fine.
- "Some company is using my open-source code according to the terms of the license, without paying me or offering me a job. They're so mean, I hate open-source!" Your fault for using a "please use my code freely" license. If you don't want your code used freely, don't use these licenses.
-
"Users feel entitled to my support, it's heartbreaking and causing me anxiety" Just ignore them! I received this gem of an email lately:
Hey there Sevagh,
I'm trying to tidy up a pitch-detector that's based on your code: https://github.com/adamski/pitch_detector
It's a generous offer for me to fix somebody else's code (loosely based on my code). For free. For some dumbass. I sent a reply and put it straight to spam:
I don't appreciate being asked to support somebody else's code (let alone my own, where free support is not something I provide).
Lessons learned from school
I don't regret going back to school, because I always intended on getting a master's degree in my life. By the end of it, I got published and wrote a lot of good code, but it certainly became a stressful drag for more than a year. Luckily, the stressful drudgery of grad school was a welcome distraction from the worst of COVID measures.
Good things
First and foremost, I learned how to create compelling presentations. I must have delivered upwards of 100 presentations; big, small, formal, informal, in-person, on Zoom, Discord, Microsoft Teams, etc. I enjoy giving presentations at work and it's because of the way I had to churn them out relentlessly during grad school. I have some LaTeX beamer skeleton files I copy-paste everywhere. I've thought of sharing them in a repository, but they can be gleaned from my existing reports anyway, without using up too much of my time to generalize them.
An advantage of Zoom university during COVID is that it let me fully participate in both my work life and academic life. Getting away from work to attend a physical space is different from taking a 30-minute break in your own home to switch computers and deliver a virtual presentation.
Next, I learned how to create good diagrams. Well, OK; I don't know if my diagrams are good. I learned how to create diagrams that I believed could show the important bullet points of my designs and ideas. Throughout this post I showed examples of the different diagrams I've created over the years to accompany my project READMEs. I only ever use Inkscape to create diagrams.
My report-writing skills must have improved, but not in a way I care about. I actually prefer the more terse and authentically confusing ways that I write my READMEs. In my written materials provided with my projects, I like to give people a tour of the state of my mind; actually explaining the library or idea is secondary.
Bad things
Academics are unreachable to a fault, and not in a way that's cute or zany:
- If you're a fancy big brain tenured professor whatever, and you lack the time management skills to read your emails, I'm not impressed
- If you're an overworked PhD candidate or student, and you lack the time management skills to read your emails, I'm not impressed
- If you're anybody at all, and you lack the time management skills to read your emails, I'm not impressed
In every situation, by ignoring my correspondence, you're telling me that your time is more important than mine; which is surely not the case, because we are both human beings that should be afforded the bare minimum of respect and communication with our professional or academic peers. I have met a lot of academics at events, described my work, had a nice conversation ending in a promise to send each other emails and keep in touch, and then: absolute silence. Where did these emails go? Do these people have no shame, lying to my face about wanting to keep in touch?
Academics don't release working code because they don't have code that works, they've never tested their idea, and cannot trust that any other person can replicate it because they simply lack the understanding of their own idea because if they believed in their own idea they would put their money where their mouth is and publish the code.
- Part of the reason I wanted to do a master's degree was that I felt uncomfortable being a scathing critic of something I wasn't a part of. Maybe there's a good reason academics don't release working code?
- I've read places that ideas are forever while the implementation can rot and needs maintenance, which is why academics don't release code. To those people, I say that if you don't have code that works, I cannot trust you that the idea is sound.
- I now believe that the only reason academics don't release code is they know their stuff doesn't work. How do papers that present ideas with no working examples that are validated or replicable pass peer review? I wish I knew. I had a problem with something in the pYIN paper that I asked about on stats.stackexchange.com. Peers, what the fuck are you doing?
- As a positive counterexample, there are many excellent initiatives today for academics to release working code, such as paperswithcode.com. The SigSep community for music demixing and source separation has a lot of available code, which hugely influenced my decision to build on top of their existing code packages and models to ultimately produce xumx-sliCQ for my thesis.
-
This comes up a lot, and usually exhausted academics say, "for the millionth time, we are not programmers! we are academics!" Ultimately, I'm guilty of this as well. Explaining every single line of code I wrote in xumx-sliCQ would've blown my thesis up to 500 pages or more, and taken 5 years to write. I had a conversation with a colleague in my research lab. Paraphrased, it went something like this:
Me: I thought I would come to academia to put my money where my mouth is and have my code and paper go hand in hand
Me: However, every time I try to include code in my thesis, I'm told I need to explain it better or omit it, because snippets of isolated code with captions like "this is how you avoid OOM errors when the numpy ndarray is too big" or "looping over a list of differently-shaped tensors to emulate a ragged matrix" do not make for good inclusions in academic papers
Me: I can either choose to omit the code, and omit the effort to explain it, or do it properly. And I choose to just omit the code so I can get my degree and get the fuck out of here
Colleague: Makes sense...
-
Regarding headbang.py and beat tracking, I tried to find some "open" beat tracking datasets used in ISMIR and MIREX, and actually couldn't! I even emailed the task captain. Ludicrous. Hidden algorithms with hidden code using hidden datasets peer reviewed by the same hidden cabal that peer-review each others' beat tracking papers. Good job, you solved beat tracking
 .
.Dear Sevag, I am sorry to tell you that I don't have/know those datasets. I was the captain on the downbeat estimation task. For the beat estimation, you can email <redacted>. Maybe he can help you. Unfortunately, even as task captains, we don't have access to the datasets used for the evaluation. I am not sure if <redacted> will be able to give these to you but he might be able to guide you toward other datasets. Good luck, <redacted>
Hello <redacted>,
I was able to find the SMC12 dataset (hosted by SMC), but I'm having a harder time finding any copies of the MCK 06 and MAZ 09 datasets available for download.
Are those available?
Academic bureaucracy is disrespectfully slow and painful. I felt more prepared and diligent as a student compared to my superiors and administrative counterparts. There are a million applicants beating down the doors of every department in every university in the developed world. Bureaucrats and professors have a license to treat you like cattle; or in fact, like children, since I also found that some professors interacted with me as if I was fresh out of undergrad. I didn't appreciate it, since I'm a 30-year-old engineer, and I suspect these are common reasons that caused some of my industry colleagues to abandon their graduate studies.
Fun fact: until I wrote my papers, there was no official definition given for music demixing as opposed to music source separation. I was asked to solve this problem; I was told "you can't just use this term without defining it!" For the sake of fuck, I was only repeating the same incompetence and omission of definition by smarter, older, more studied, more peer reviewed, more tenured professors and academics who created the field and it's my fault?? The entire academic world of source separation is fine to proceed without providing definitions for their made-up terms without getting dinged even once in peer review; in IEEE, in ISMIR, in DAFx, everywhere. Basically, "rules for thee not for me," making a fucking baby beginner master's student do the job that academics who invented terminology should have been doing; what are peer reviewers doing, if not raising these issues?